[번역] 그림으로 설명하는 Retrieval Transformer
The Illustrated Retrieval Transformer
이 글은 Jay Alammar님의 글을 번역한 글입니다. [추가정보] This post is a translated version of The Illustrated Retrieval Transformer) by Jay Alammar.
요약: 최신 언어 모델 batch는 매우 작지만 DB를 쿼리하거나 웹에서 정보를 검색할 수 있어서 GPT-3와 같은 성능을 달성할 수 있습니다. 우리가 주목해봐야하는 점은 성능을 향상하기 위한 유일한 방법이 더 큰 모델을 build하는 것이 아니라는 것입니다. Summary: The latest batch of language models can be much smaller yet achieve GPT-3 like performance by being able to query a database or search the web for information. A key indication is that building larger and larger models is not the only way to improve performance.
최근 몇년간 우리는 거대 언어 모델(LLM; Large Language Model)들의 등장을 봤습니다 – 어떻게 기계가 (인간의) 언어를 처리하고 생성하는 방식을 빠르게 개선한 기계 학습(ML; Machine Learning) 모델입니다. 2017년 이후 하이라이트는 다음과 같습니다: The last few years saw the rise of Large Language Models (LLMs) – machine learning models that rapidly improve how machines process and generate language. Some of the highlights since 2017 include:
- 최초의 Transformer는 기계 번역의 이전 성능 기록을 경신했습니다.
- BERT는 pre-training 후 finetuning 프로세스와 Transformer 기반의 contextual word embedding을 대중화합니다. 그리고 빠르게 Google 검색 및 Bing 검색에 파워를 넣기 시작합니다.
- GPT-2는 기계가 인간처럼 글을 쓰는 능력을 보여줍니다.
- 먼저 T5가, 그 뒤로는 T0가 transfer learning (한 task에서 모델을 훈련시킨 후, 거기서 얻은 정보를 바탕으로 다른 비슷한 task에 대해 잘 수행하도록 함) 및 text-to-text task들 처럼 많은 다형의 task들을 수행하는 것의 경계를 확장합니다.
- GPT-3는 생성 모델의 대규모 스케일링(크기 확장)이 충격적인 새로운 어플리케이션으로 이어질 수 있음을 보여주었습니다 (업계에서는 Gopher, MT-NLG 등과 같이 더 큰 모델을 꾸준히 학습하고 있습니다). * The original Transformer breaks previous performance records for machine translation. * BERT popularizes the pre-training then finetuning process, as well as Transformer-based contextualized word embeddings. It then rapidly starts to power Google Search and Bing Search. * GPT-2 demonstrates the machine’s ability to write as well as humans do. * First T5, then T0 push the boundaries of transfer learning (training a model on one task, and then having it do well on other adjacent tasks) and posing a lot of different tasks as text-to-text tasks. * GPT-3 showed that massive scaling of generative models can lead to shocking emergent applications (the industry continues to train larger models like Gopher, MT-NLG…etc).
한동안은 모델의 크기를 확장해나가는 것이 성능을 향상시키는 주요 방법인 것처럼 보였습니다. 하지만 DeepMind의 RETRO Transformer 및 OpenAI의 WebGPT와 같은 이 분야의 최근 개발에서, 정보를 검색/쿼리하는 방법으로 확장한다면 작은 생성 언어 모델도 거대 모델과 동등한 성능을 발휘할 수 있음을 보여줌으로써 트렌드를 바꿔놓았습니다. For a while, it seemed like scaling larger and larger models is the main way to improve performance. Recent developments in the field, like , reverse this trend by showing that smaller generative language models can perform on par with massive models if we augment them with a way to search/query for information.
이 글은 DeepMind의 RETRO (Retrieval-Enhanced TRansfOrmer)와 그 동작방식을 설명합니다. 이 모델은 사이즈가 4% (75억개 파라미터 vs. GPT-3 다빈치 모델의 경우 1850억개 파라미터) 밖에 되지 않지만 GPT-3와 유사하게 성능을 냅니다. This article breaks down DeepMind’s RETRO (Retrieval-Enhanced TRansfOrmer) and how it works. The model performs on par with GPT-3 despite being 4% its size (7.5 billion parameters vs. 185 billion for GPT-3 Da Vinci).
RETRO는 database에서 retrieval된 정보를 추가하여, 파라미터들이 fact와 world knowledge의 값비싼 저장소가 되는 것을 방지합니다.
RETRO는 Improving Language Models by Retrieving from Trillions of Tokens 논문에 기술되어 있습니다. 연구 커뮤니티에서 넓고 다양한 retrival work가 꾸준히 build되고 있습니다. (참고: 1 2 3 4 5) 이 글은 RETRO 모델에 대한 설명이며, 모델의 참신성에 대한 것은 아닙니다. RETRO was presented in the paper Improving Language Models by Retrieving from Trillions of Tokens. It continues and builds on a wide variety of retrieval work in the research community. This article explains the model and not what is especially novel about it.
중요한 이유: 언어 정보를 World Knowledge 정보와 분리시킴
Why This is Important: Separating Language Information from World Knowledge Information
언어 모델링은 기본적으로 문장 끝의 빈칸(blank)을 채우기 위해 다음 단어를 예측하도록 모델을 학습합니다. Language modeling trains models to predict the next word–to fill-in-the-blank at the end of the sentence, essentially.
빈칸을 채우는 것은 가끔 사실 정보 (예. 이름 또는 날짜)의 지식이 필요합니다. 예를 들면: Filling the blank sometimes requires knowledge of factual information (e.g. names or dates). For example:

입력 프롬프트: 영화 듄은 출시(시간정보)가 ....(이다).
다른 경우에는, 해당 언어에 대한 친숙도가 빈칸에 들어갈 내용을 추측하기에 충분합니다. 예를 들어: Other times, familiarity with the language is enough to guess what goes in the blank. For example:

입력 프롬프트: 입소문으로 퍼진 인기가 Herbert가 시작할 수 있게 했습니다, 본격적인 ....(을).
이 구분은 LLM이 알고 있는 모든 것을 모델 파라미터에 인코딩하기 때문에 중요합니다. 이 것은 언어 정보에 대해서는 타당하지만, fact 및 world-knowledge 정보에 대해서는 비효율적입니다. This distinction is important because LLMs encoded everything they know in their model parameters. While this makes sense for language information, it is inefficient for factual and world-knowledge information.
언어 모델에 retrieval 방법을 추가함으로써, 모델은 훨씬 작아질 수 있습니다. neural database는 텍스트 생성 중에 필요한 fact 정보를 retrieving 하는 것에 도움이 됩니다. By including a retrieval method in the language model, the model can be much smaller. A neural database aids it with retrieving factual information it needs during text generation.
retrieval 방법으로 언어 모델을 지원하는 것은, 언어 모델이 텍스트를 잘 생성하기 위해 파라미터에 인코딩하는 정보의 양(크기)를 줄일 수 있게 합니다.
훈련 데이터 암기(memorization)가 줄어들기 때문에 작은 언어 모델로 훈련이 빨라집니다. 누구나 작고 저렴한 GPU를 이용하여 이런 작은 모델들을 deploy할 수 있고 필요에 따라 조정할 수 있습니다. Training becomes fast with small language models, as training data memorization is reduced. Anyone can deploy these models on smaller and more affordable GPUs and tweak them as per need.
구조적으로, RETRO는 최초의 transformer와 같은 encoder-decoder 모델입니다. 하지만 retrieval database의 도움으로 입력 시퀀스가 보강됩니다. 모델은 database에서 가장 유력한 시퀀스를 찾고 입력에 추가합니다. 그러면 RETRO는 출력 예측을 생성하기 위한 마법을 겁니다. Mechanically, RETRO is an encoder-decoder model just like the original transformer. However, it augments the input sequence with the help of a retrieval database. The model finds the most probable sequences in the database and adds them to the input. RETRO works its magic to generate the output prediction.
RETRO는 database를 활용하여 입력 프롬프트를 보강합니다. 프롬프트는 관련 정보를 database에서 retrieve하는데 사용됩니다.
모델 아키텍처를 보기 전에, retrieval database에 대해 깊이 있게 알아보겠습니다. Before we explore the model architecture, let’s dig deeper into the retrieval database.
RETRO의 Retrieval Database 세부 사항
Inspecting RETRO’s Retrieval Database
database는 key-value 저장소입니다. The database is a key-value store.
key는 일반적으로 사용하는 BERT 문장 임베딩입니다. The key is a standard BERT sentence embedding.
value는 2파트의 텍스트로 되어있습니다: The value is text in two parts:
- Neighbor: key를 계산하기 위해 사용됨
- Completion: 원본 문서에서 text의 연속 (Neighbor 문장에서의 연속적으로 연결된 다음 텍스트)
- Neighbor, which is used to compute the key
- Completion, the continuation of the text in the original document. </span>
RETRO에서의 database는 MassiveText 데이터셋으로부터의 2조개의 다국어(multi-lingual) 토큰을 가지고 있습니다. 길이는 neighbor chunk와 completion chunk 모두 최대 64개 토큰까지 가능합니다. RETRO’s database contains 2 trillion multi-lingual tokens based on the MassiveText dataset. Both the neighbor and completion chunks are at most 64 tokens long.

RETRO database의 내부를 살펴보면 RETRO database의 key-value 쌍의 예를 볼 수 있습니다. value는 neighbor chunk와 completion chunk를 포함합니다. A look inside RETRO's database shows examples of key-value pairs in the RETRO database. The value contains a neighbor chunk and a completion chunk.
RETRO는 입력 프롬프트르르 여러개의 chunk로 쪼갭니다. 단순하게 설명하기 위해, 하나의 chunk가 retreive된 text로 보강되는 방법을 집중해서 살펴보겠습니다. 하지만, 모델은 입력 프롬프트에서 (첫번째를 제외하고) 각 chunk에 대해 이 프로세스를 수행합니다. RETRO breaks the input prompt into multiple chunks. For simplicity, we’ll focus on how one chunk is augmented with retrieved text. The model, however, does this process for each chunk (except the first) in the input prompt.
Database 조회
The Database Lookup
RETRO에 들어가기 전에 입력 프롬프트는 BERT에 먼저 입력됩니다. 출력 contextualized vector들은 평균이 계산되어 문장 임베딩 벡터를 구성됩니다. 그렇게 만들어진 벡터는 database를 쿼리하는데에 사용됩니다. Before hitting RETRO, the input prompt goes into BERT. The output contextualized vectors are then averaged to construct a sentence embedding vector. That vector is then used to query the database.
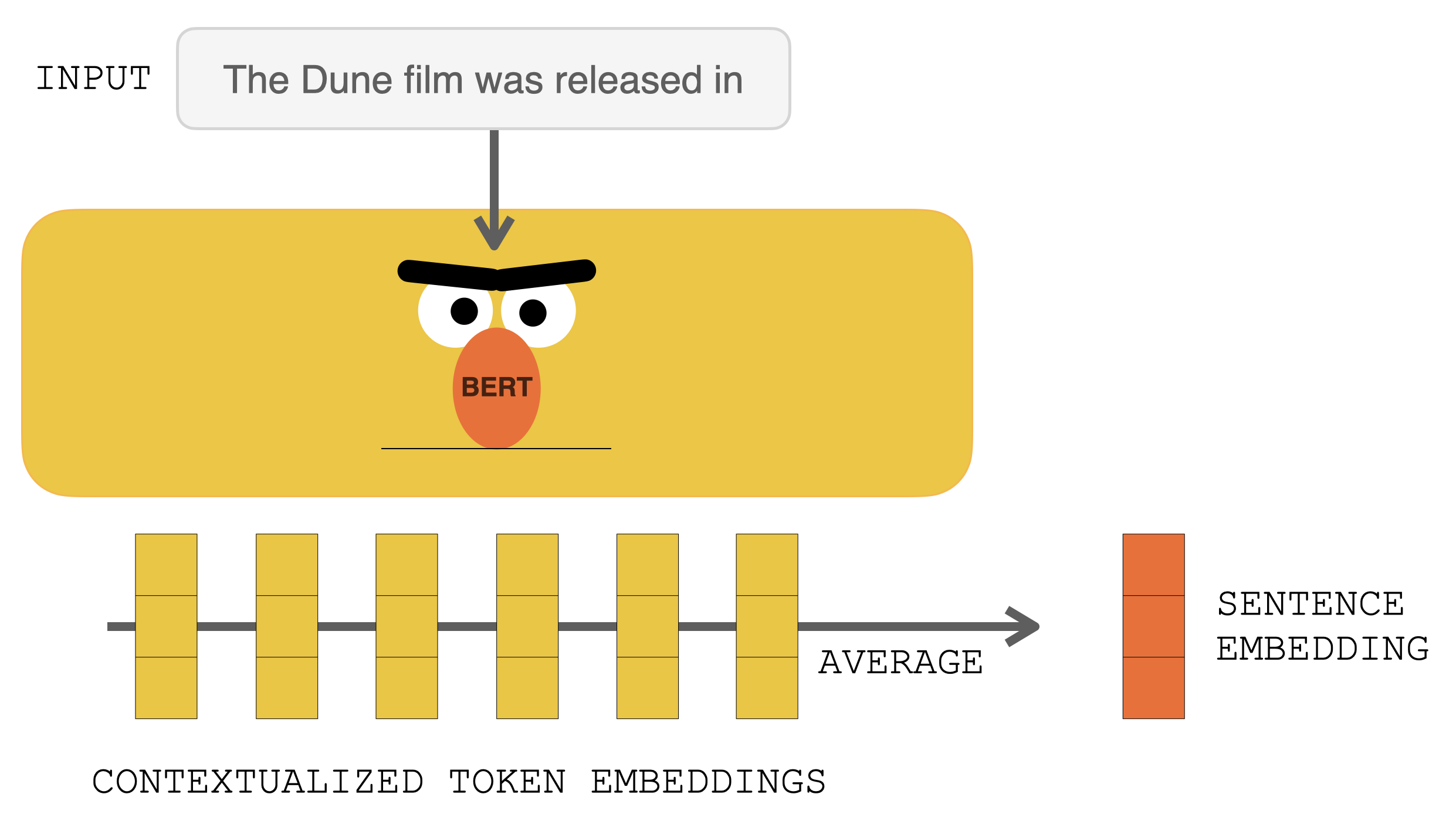
BERT로 입력 프롬프트를 처리하면 contextualized 토큰 임베딩이 생성됩니다. 그 결과들을 평균을 계산해서 문장 임베딩을 생성합니다. Processing the input prompt with BERT produces contextualized token embeddings. Averaging them produces a sentence embedding.
그 문장 임베딩은 근사 근접 이웃 탐색(approximate nearest neighbor search)에서 사용됩니다. That sentence embedding is then used in an approximate nearest neighbor search (https://github.com/google-research/google-research/tree/master/scann).
두개의 근접 이웃이 retrieve되고, 그 텍스트가 RETRO의 입력의 일부가 됩니다. The two nearest neighbors are retrieved, and their text becomes a part of the input into RETRO.
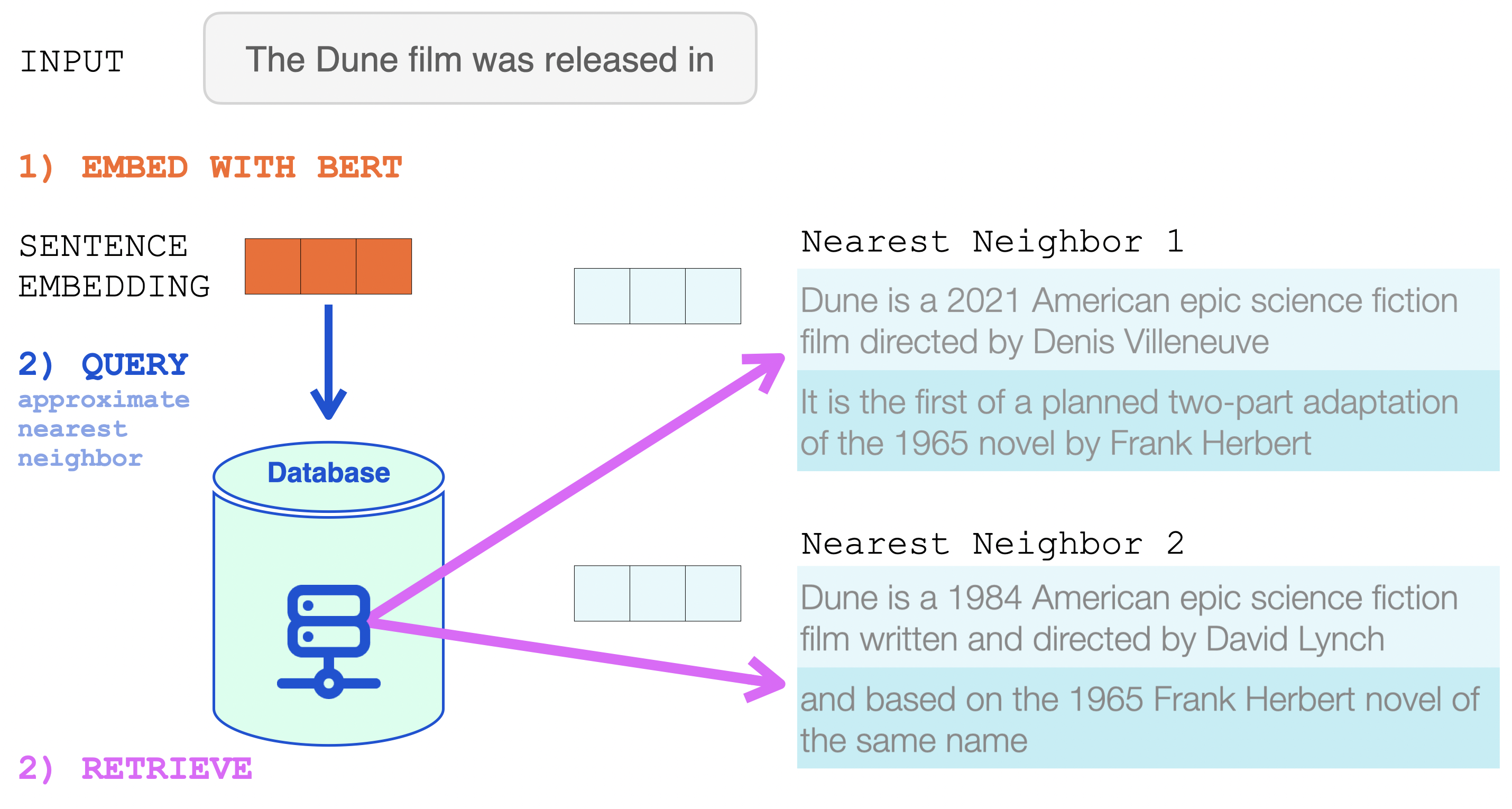
BERT 문장 임베딩은 RETRO의 neural database에서 근접 이웃을 retrieve하는데에 사용됩니다. 검색된 결과들을 언어 모델의 입력에 추가됩니다.
RETRO의 입력은, 입력 프롬프트와 (입력 프롬프트로를) database에서 검색한 두개의 근접 이웃 (및 그들의 continuation(연결된 다음 문장))입니다. This is now the input to RETRO. The input prompt and its two nearest neighbors from the database (and their continuations).
이제 Transformer와 RETRO는 정보를 통합하고, 프로세싱을 합니다. From here, the Transformer and RETRO Blocks incorporate the information into their processing.
retrieve된 이웃은 언어 모델의 입력에 추가됩니다. 하지만, 그 이웃들은 모델 안에서 조금 다르게 처리됩니다.
RETRO 아키텍처 조망
RETRO Architecture at a High Level
RETRO 아키텍처는 인코더 스택과 디코더 스택으로 구성되어 있습니다. RETRO’s architecture is an encoder stack and a decoder stack.
RETRO transformer는 (neighbor들을 처리하기 위한) 인코더 스택과 (입력을 처리하기 위한) 디코더 스택으로 구성되어 있습니다.
인코더는 기본 Transformer 인코더 블록(self-attention + FFNN)들으로 구성되어 있습니다. 제가 알기로는, Retro는 두개의 Transformer 인코더 블럭으로 구성된 인코더를 사용합니다. The encoder is made up of standard Transformer encoder blocks (self-attention + FFNN). To my best understanding, Retro uses an encoder made up of two Transformer Encoder Blocks.
디코더 스택은 두 종류의 디코더 블록을 interleave(사이에 끼워넣음) 합니다: The decoder stack interleaves two kinds of decoder blocks:
- 기본 transformer 디코더 블록 (ATTN + FFNN)
- RETRO 디코더 블록 (ATTN + CCA(Chunked Cross Attention) + FFNN) * Standard transformer decoder block (ATTN + FFNN) * RETRO decoder block (ATTN + Chunked cross attention (CCA) + FFNN)
세 종류의 Transformer 블록이 RETRO를 구성합니다.
retrive된 이웃을 처리하여, 나중에 attention을 위해 사용될 KEYS 및 VALUES 행렬을 생성하는 인코더 스택부터 살펴보겠습니다 (복습을 위해 The Illustrated Transformer 참고하세요). Let’s start by looking at the encoder stack, which processes the retrieved neighbors, resulting in KEYS and VALUES matrices that will later be used for attention (see The Illustrated Transformer for a refresher).
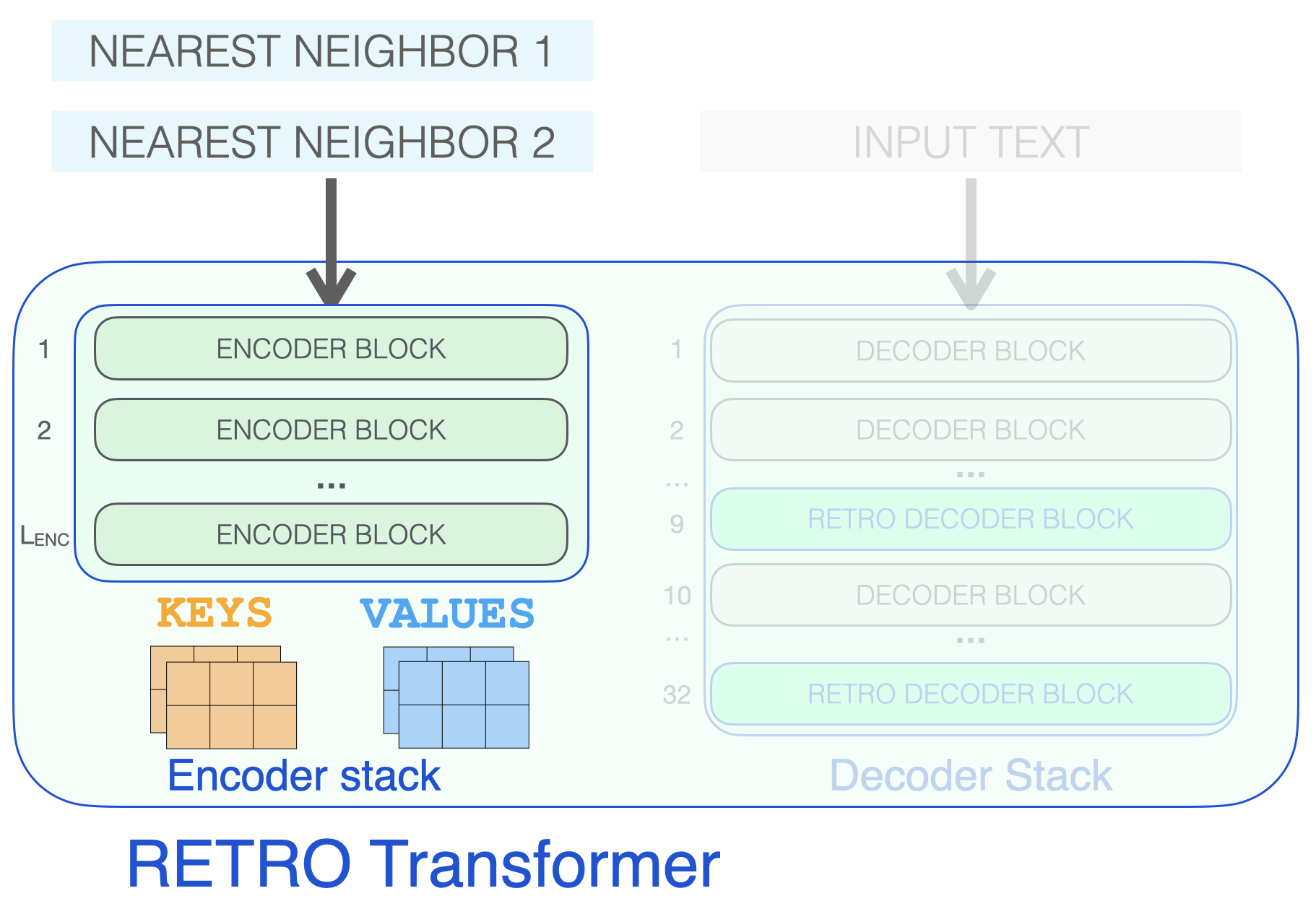
인코더 스택은 retrive된 이웃을 처리하여 KEYS 및 VALUES 행렬을 생성합니다.
디코더 블락은 입력 텍스트를 GPT가 하는 것 처럼 처리합니다. 프롬프트 token에 self-attention을 적용시키고 (인과적으로, 이전 토큰에만 attention을 줌), FFNN 레이어를 통과시킵니다. Decoder blocks process the input text just like a GPT would. It applies self-attention on the prompt token (causally, so only attending to previous tokens), then passes through a FFNN layer.
입력 프롬프트는 self-attention 및 FFNN 레이어를 포함하는 일반 디코더 블록을 통과합니다.
RETRO 디코더에 도달해서야 retrieve된 정보를 통합하기 시작합니다. 9번 이후의 매 세번째 블록들은 RETRO 블록입니다 (입력을 이웃에 attention을 줄 수 있도록 합니다). 그래서 9, 12, 15…32는 RETRO 블록입니다. (두개의 더 작은 Retro 모델과 Retrofit 모델들은 9번째가 아닌 6번째 부터 이러한 레이어들이 시작됩니다.) It’s only when a RETRO decoder is reached do we start to incorporate the retrieved information. Every third block starting from 9 is a RETRO block (that allows its input to attend to the neighbors). So layers 9, 12, 15… are RETRO blocks. (The two smaller Retro models, and the Retrofit models have these layers starting from the 6th instead of the 9th layer).
</span>
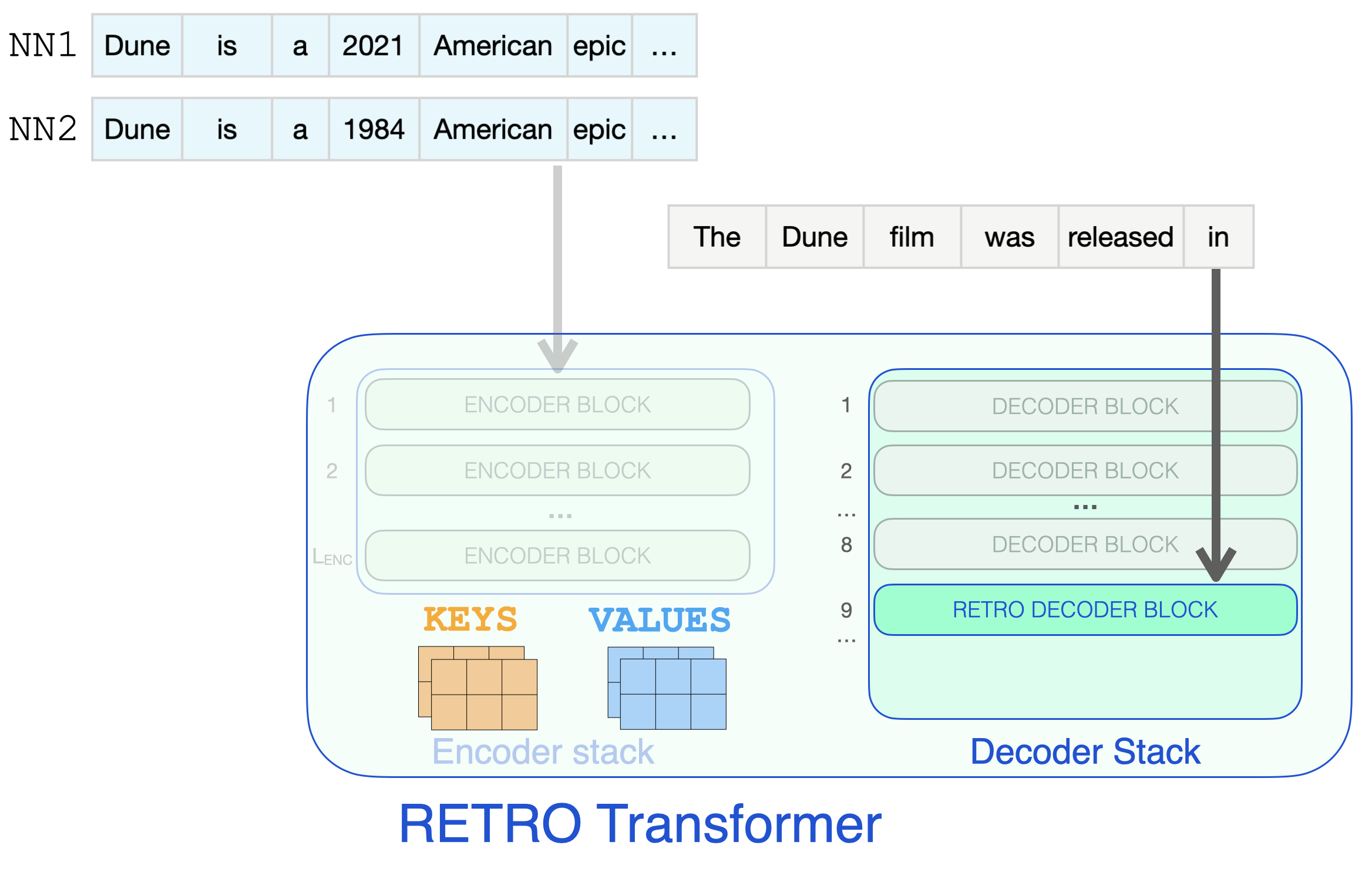
입력 프롬프트는 RETRO 디코더 블록에 도달하고 정보 retrieval이 시작됩니다.
retrieve된 정보가 프롬프트를 완료하는데 필요한 날짜 정보를 한눈에 볼 수 있는 효과적인 단계입니다. So effectively, this is the step where the retrieved information can glance at the dates it needs to complete the prompt.
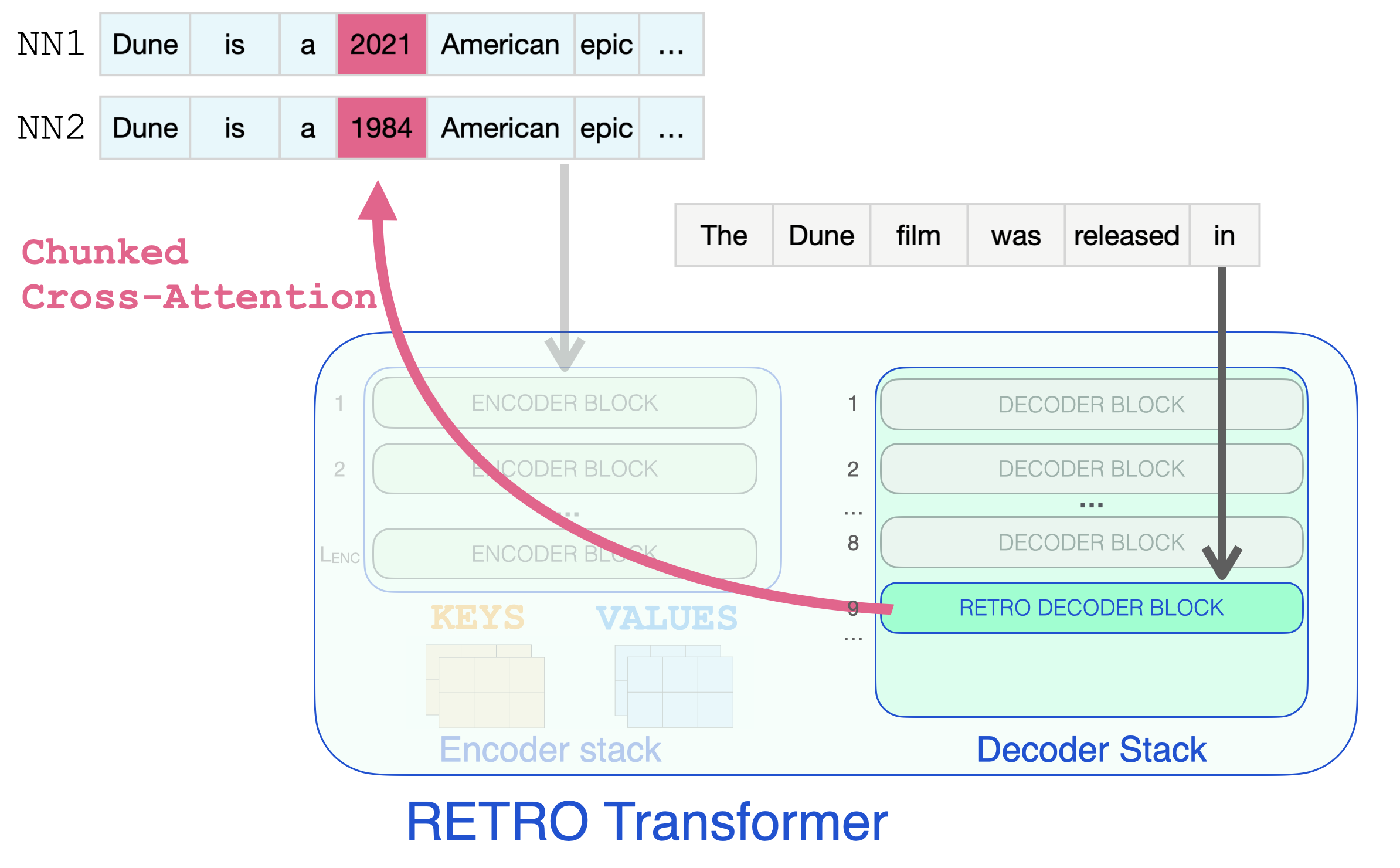
Chunked Cross-Attention을 이용하여 근접 이웃 chunk로 부터 정보를 retrieving하는 RETRO 디코더 블록.
이전 연구
Previous Work
retrieval 기술로 언어 모델을 지원하는 것은 활발한 연구 영역입니다. 이전 연구들은 다음과 같습니다: Aiding language models with retrieval techniques has been an active area of research. Some of the previous work in the space includes:
- Improving Neural Language Models with a Continuous Cache
- Generalization through Memorization: Nearest Neighbor Language Models
- Read the Retrieval Augmented Generation blog from Meta AI and go through Jackie Chi Kit Cheung’s lecture on Leveraging External Knowledge in Natural Language Understanding Systems
- SPALM: Adaptive Semiparametric Language Models
- DPR: Dense Passage Retrieval for Open-Domain Question Answering
- REALM: Retrieval-Augmented Language Model Pre-Training
- FiD: Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering
- EMDR: End-to-End Training of Multi-Document Reader and Retriever for Open-Domain Question Answering
- BlenderBot 2.0: Internet-Augmented Dialogue Generation
수정사항이나 피드백이 있으시면, 이 쓰레드에 글을 남겨주시거나 이 트위터로 연락 주세요. Please post in this thread or reach out to me on Twitter for any corrections or feedback.
추가 정보.
- 이 글은 GPT2에 대해 이해하기 쉽게 그림으로 설명한 포스팅을 저자인 Jay Alammar님의 허락을 받고 번역한 글 입니다. 원문은 The Illustrated Retrieval Transformer에서 확인하실 수 있습니다.
- 원서/영문블로그를 보실 때 term에 대한 정보 호환을 위해, 이 분야에서 사용하고 있는 단어, 문구에 대해 가급적 번역하지 않고 원문 그대로 두었습니다. 그리고, 직역 보다는 개념이나 의미에 대한 설명을 쉽게 하는 문장 쪽으로 더 무게를 두어 번역 했습니다. 번역에 대한 의견이나 수정 사항은 아래 댓글 창에 남겨주세요.
- 번역문에 대응하는 영어 원문을 보고싶으신 분들을 위해 찬님께서 만들어두신 툴팁 도움말 기능(해당 문단에 마우스를 올리면 (모바일의 경우 터치) 원문을 확인할 수 있는 기능)을 가져와서 적용했습니다. 감사합니다.