[번역] GPT3가 작동하는 방법 - 시각화 및 동영상 설명
How GPT3 Works - Visualizations and Animations
이 글은 Jay Alammar님의 글을 번역한 글입니다. [추가정보] This post is a translated version of How GPT3 Works - Visualizations and Animations by Jay Alammar.
요즘(GPT3가 릴리즈 되었을 당시) 기술분야에서는 GPT3에 대한 많은 이야기를 합니다. (GPT3와 같은) 대규모 언어 모델들은 그 능력으로 우리를 놀래키기 시작했습니다. 대부분의 비즈니스에서 고객용으로 사용하기에 충분히 신뢰성(reliable)이 있다고 할 수는 없지만, 이 모델들은 자동화(automation)로의 꾸준한 전환과 지능형 컴퓨터 시스템의 가능성을 가속화할 영리함의 번뜩이는 순간들을 보여주고 있습니다. The tech world is abuzz with GPT3 hype. Massive language models (like GPT3) are starting to surprise us with their abilities. While not yet completely reliable for most businesses to put in front of their customers, these models are showing sparks of cleverness that are sure to accelerate the march of automation and the possibilities of intelligent computer systems. Let’s remove the aura of mystery around GPT3 and learn how it’s trained and how it works.
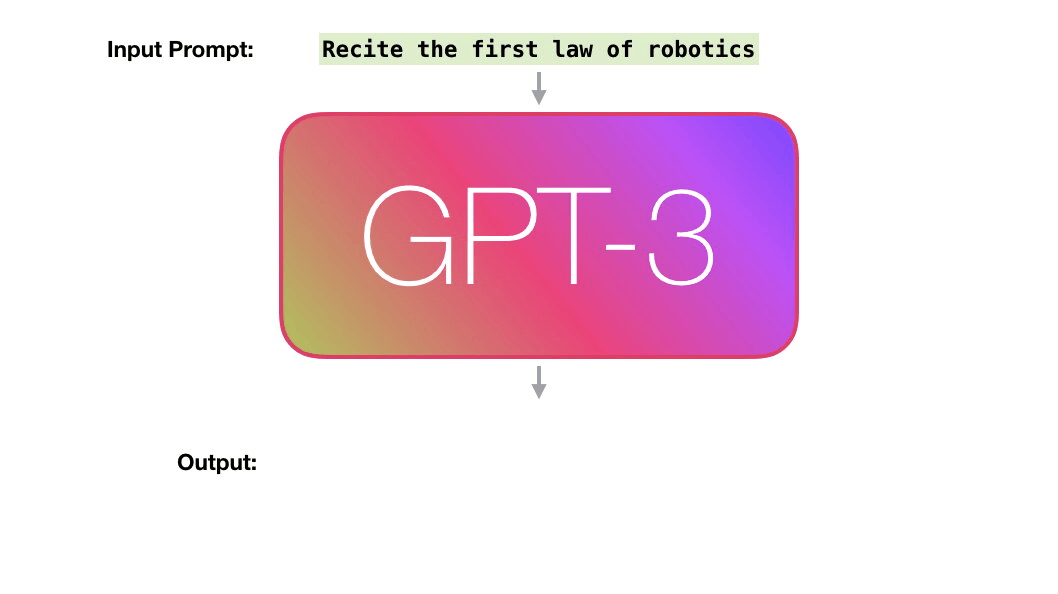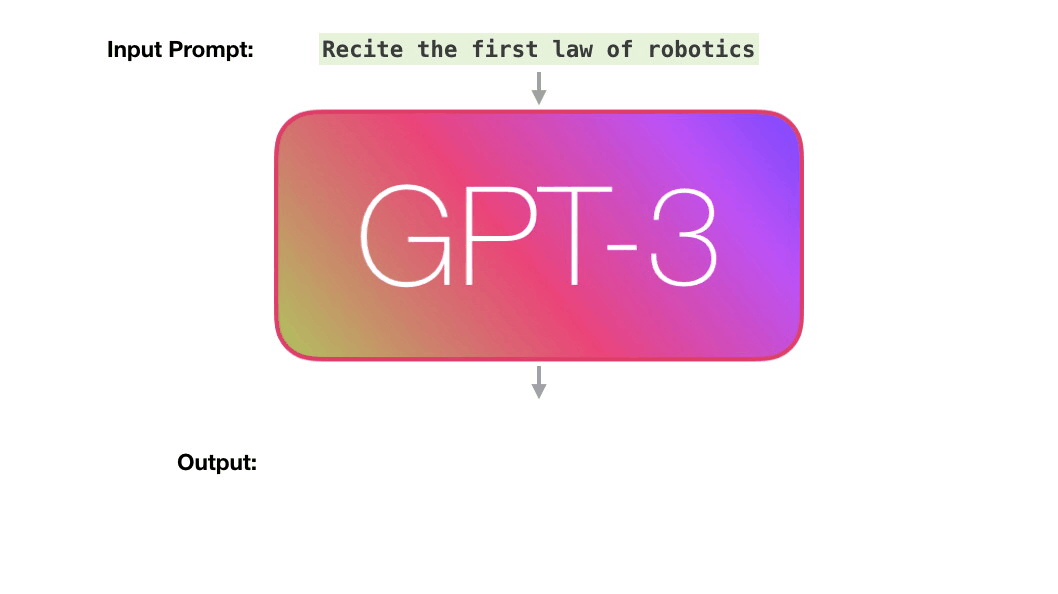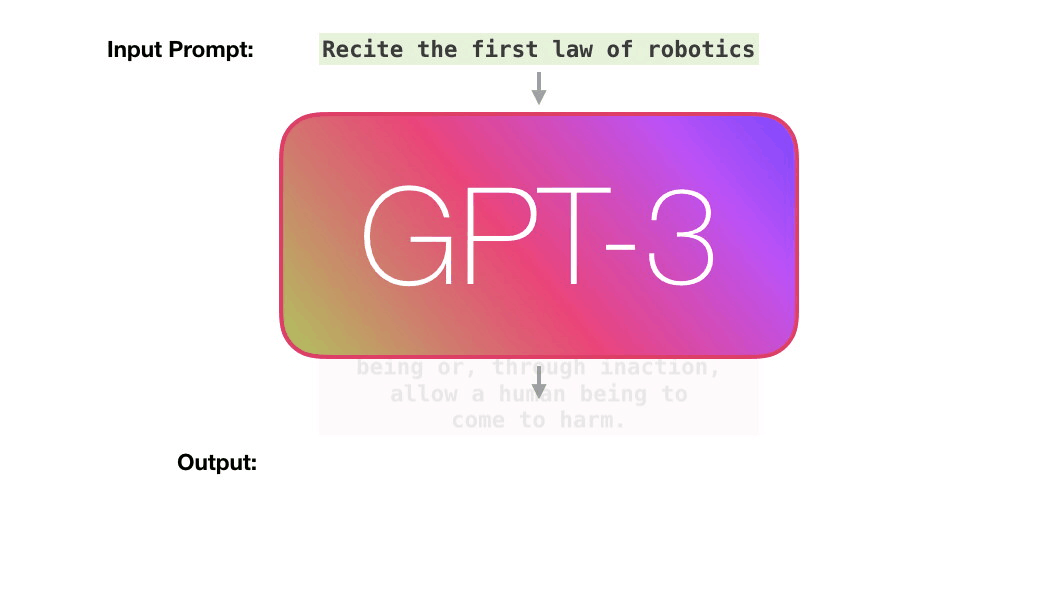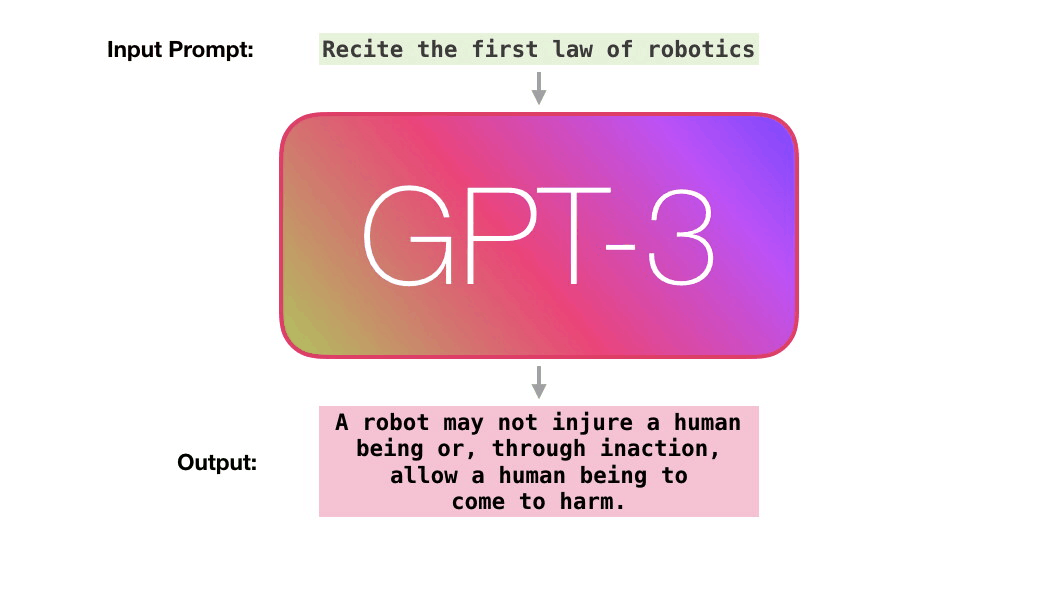
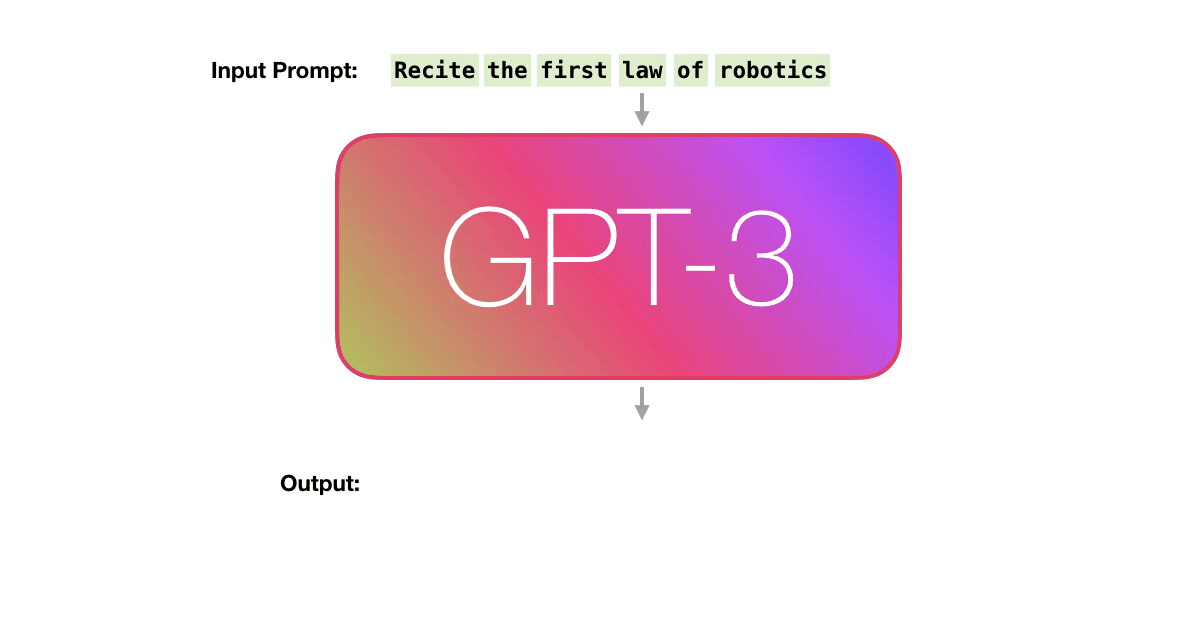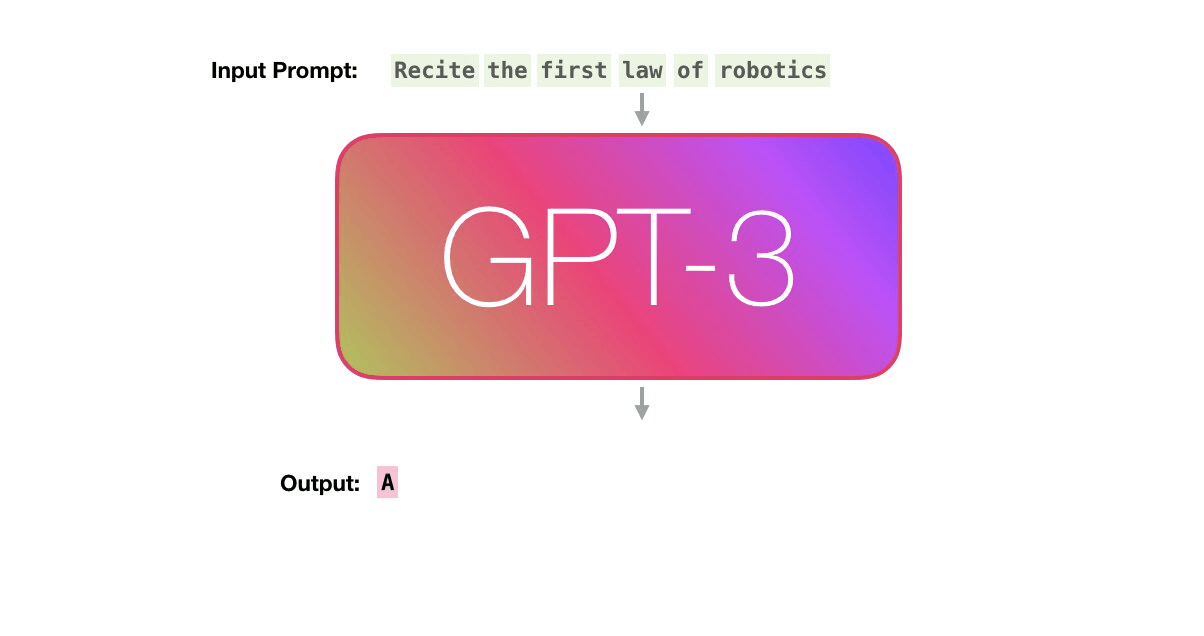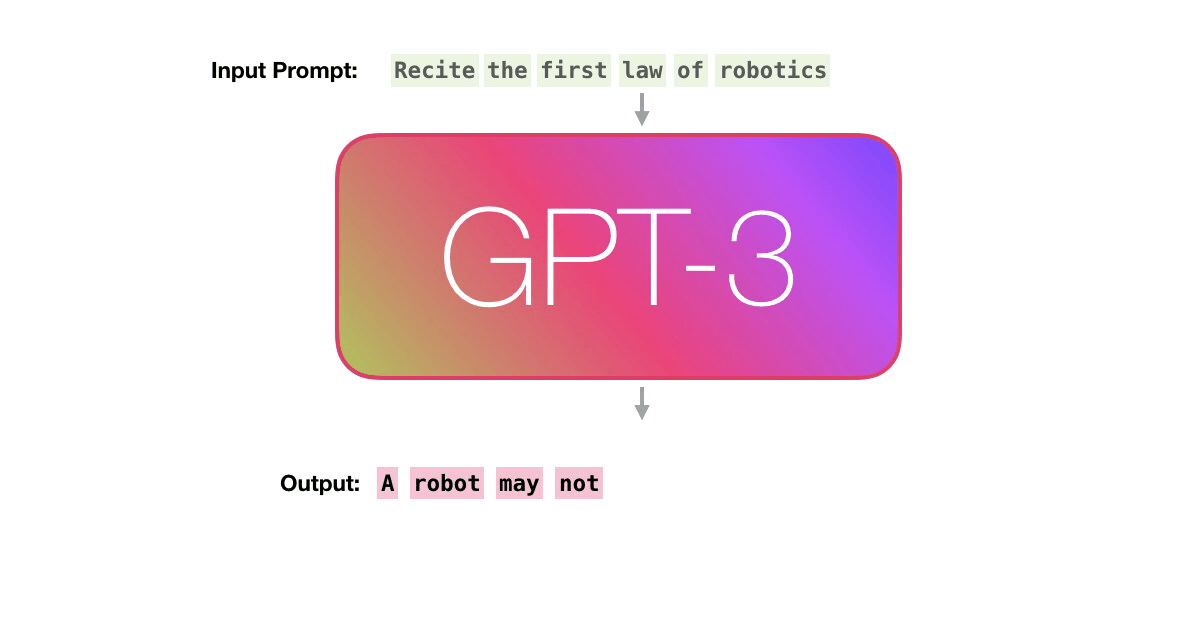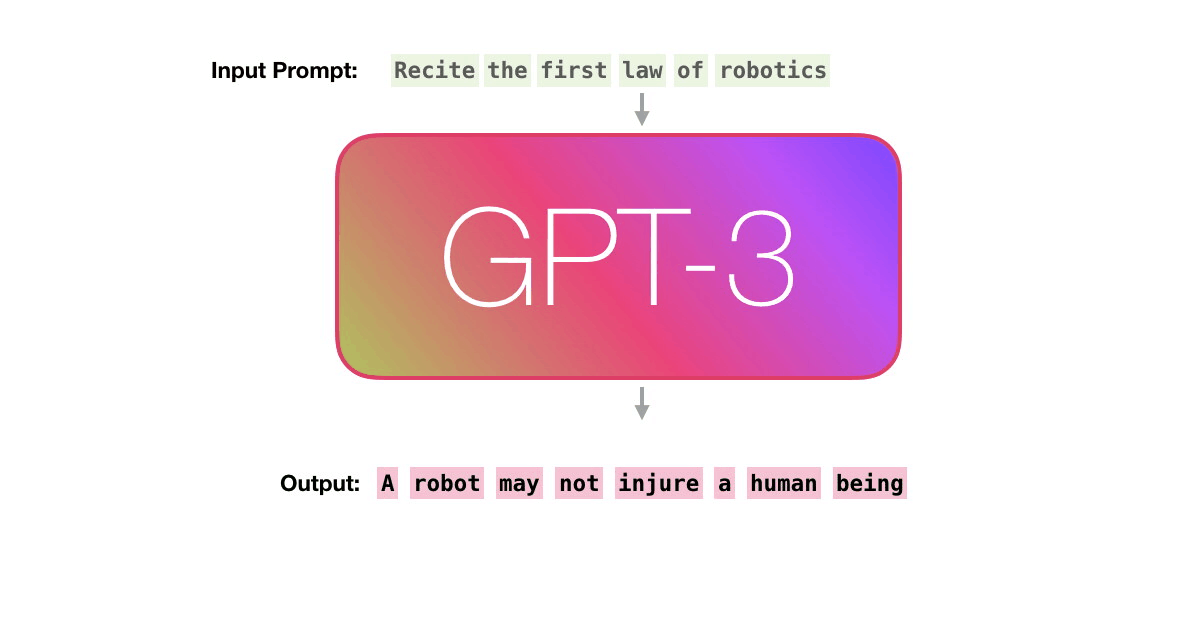
훈련된 모델은 텍스트를 생성합니다. A trained language model generates text.
선택적으로 일부 텍스트를 입력으로 넣을 수 있으며, 출력에 영향을 줍니다. We can optionally pass it some text as input, which influences its output.
대량의 텍스트를 읽는(scan하는) 훈련 기간동안 “학습된” 모델로 부터 출력이 생성됩니다. The output is generated from what the model “learned” during its training period where it scanned vast amounts of text.
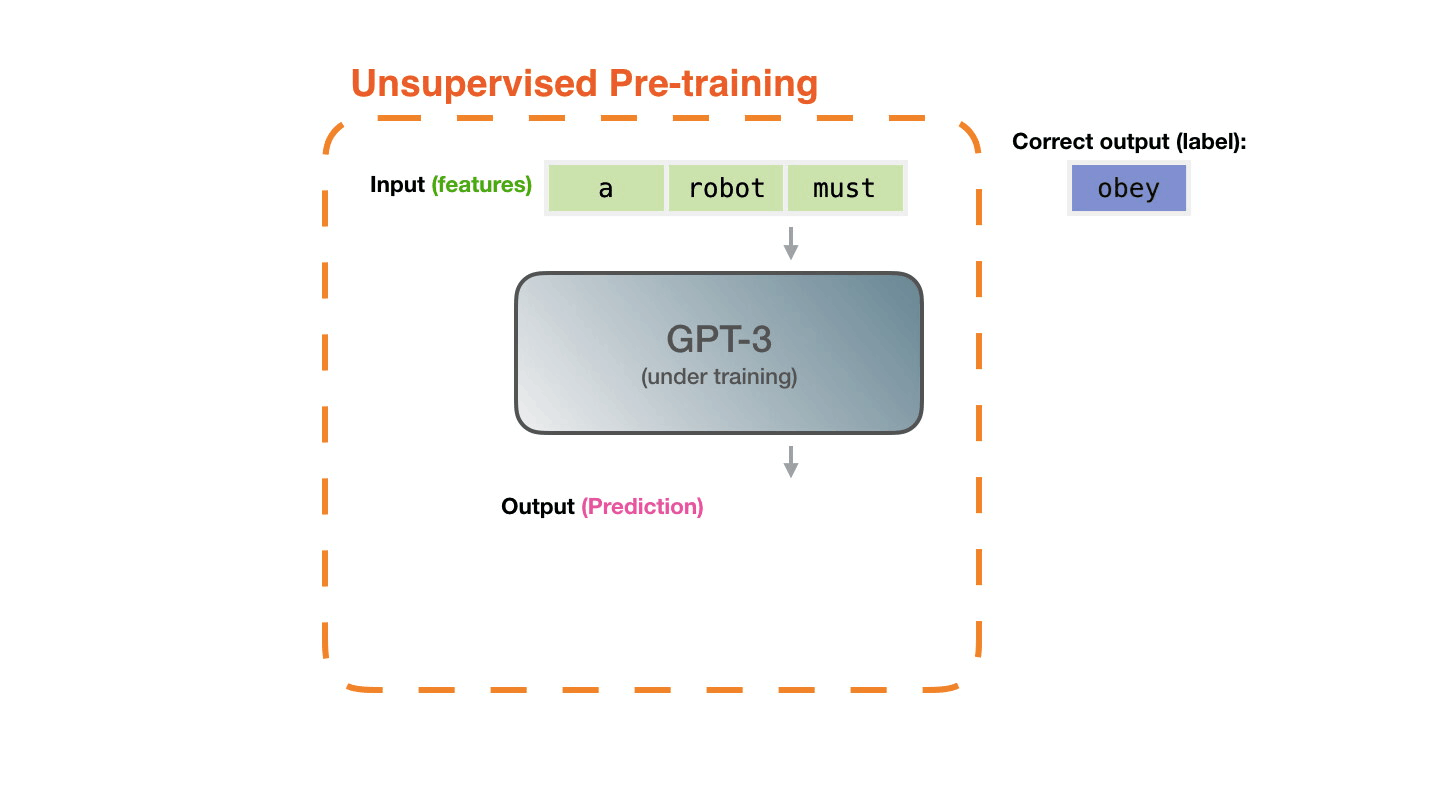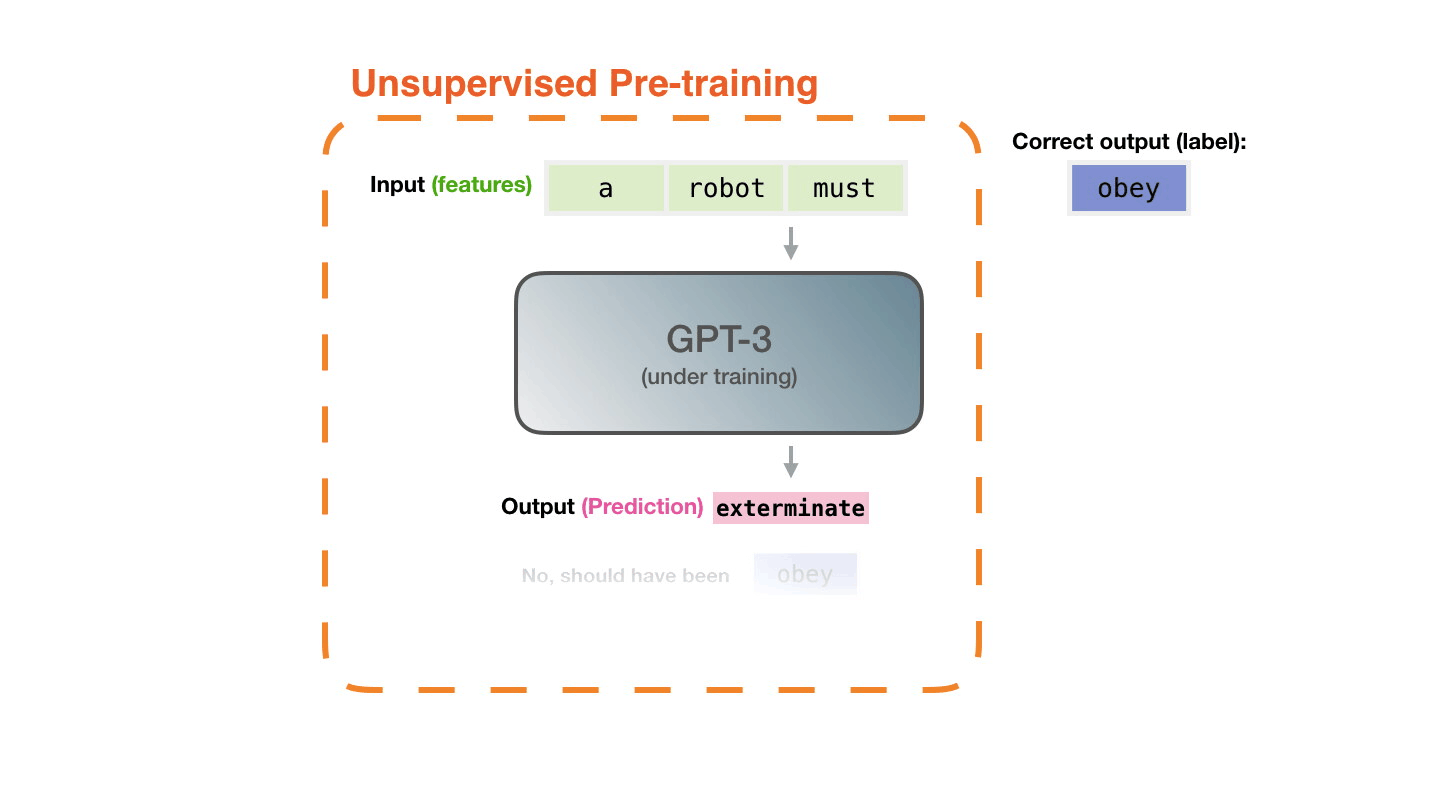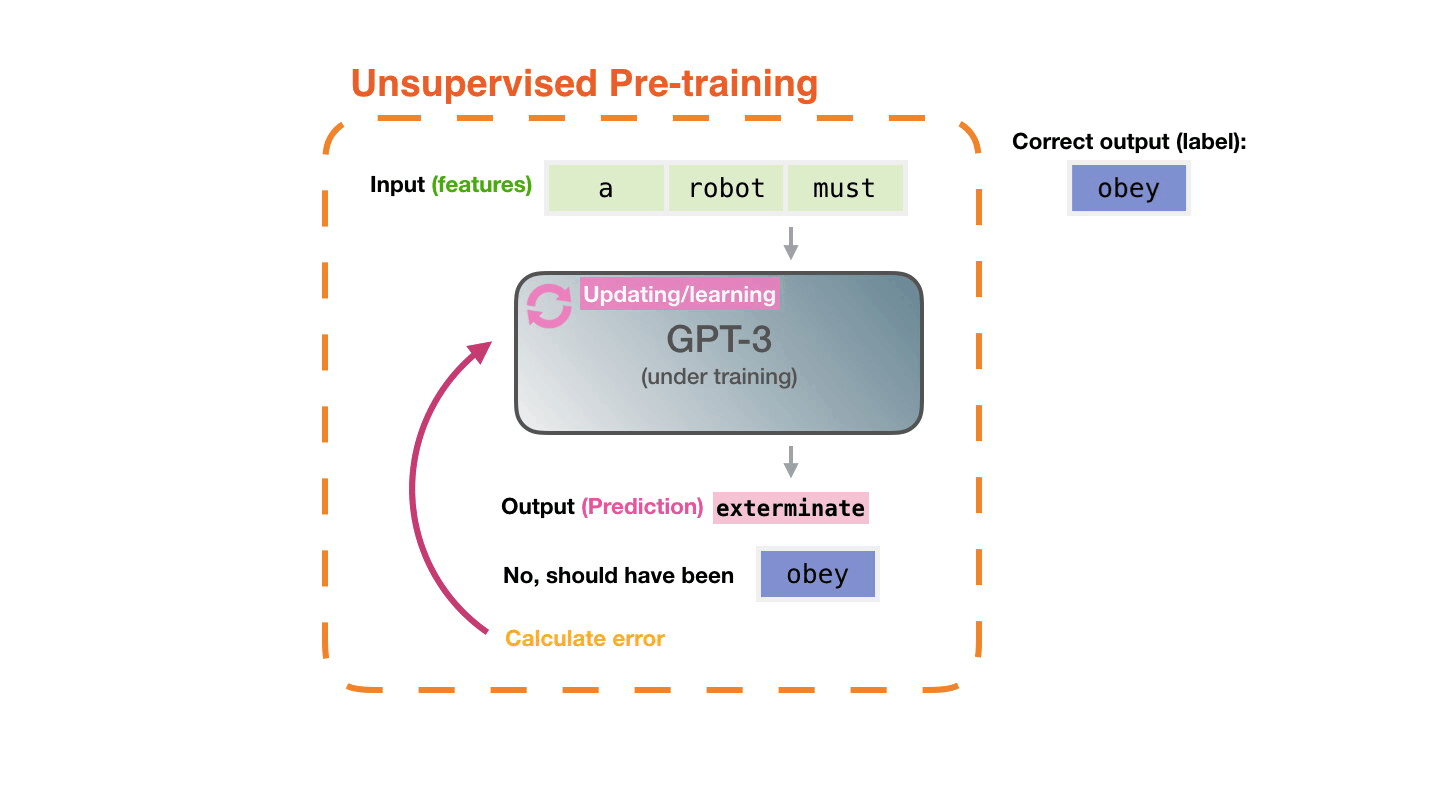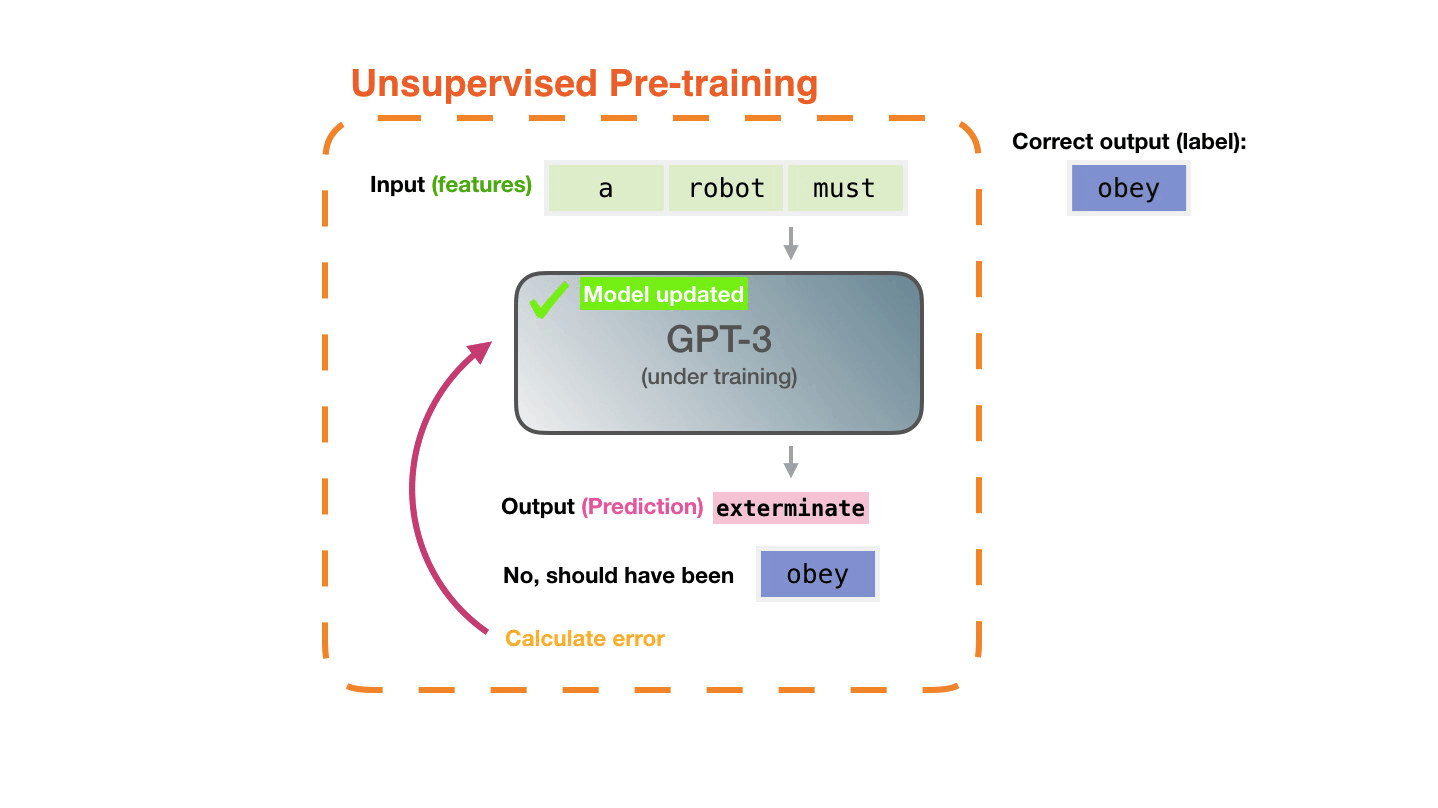
훈련은 모델에게 많은 텍스트를 노출시키는 일련의 과정입니다. 바로 그 GPT3 훈련 과정이 완료되었습니다([추가설명] GPT-3가 공개된 바로 그 시점). (커뮤니티/소셜/유투브 등에서) 지금 보고 계신 모든 실험들은, 바로 그 훈련된 모델로부터 나온 것입니다. 그 모델은 355년(GPU; V100기준) 및 460만 달러($4.6m)가 소비/소요되는 것으로 예상합니다. Training is the process of exposing the model to lots of text. That process has been completed. All the experiments you see now are from that one trained model. It was estimated to cost 355 GPU years and cost $4.6m.
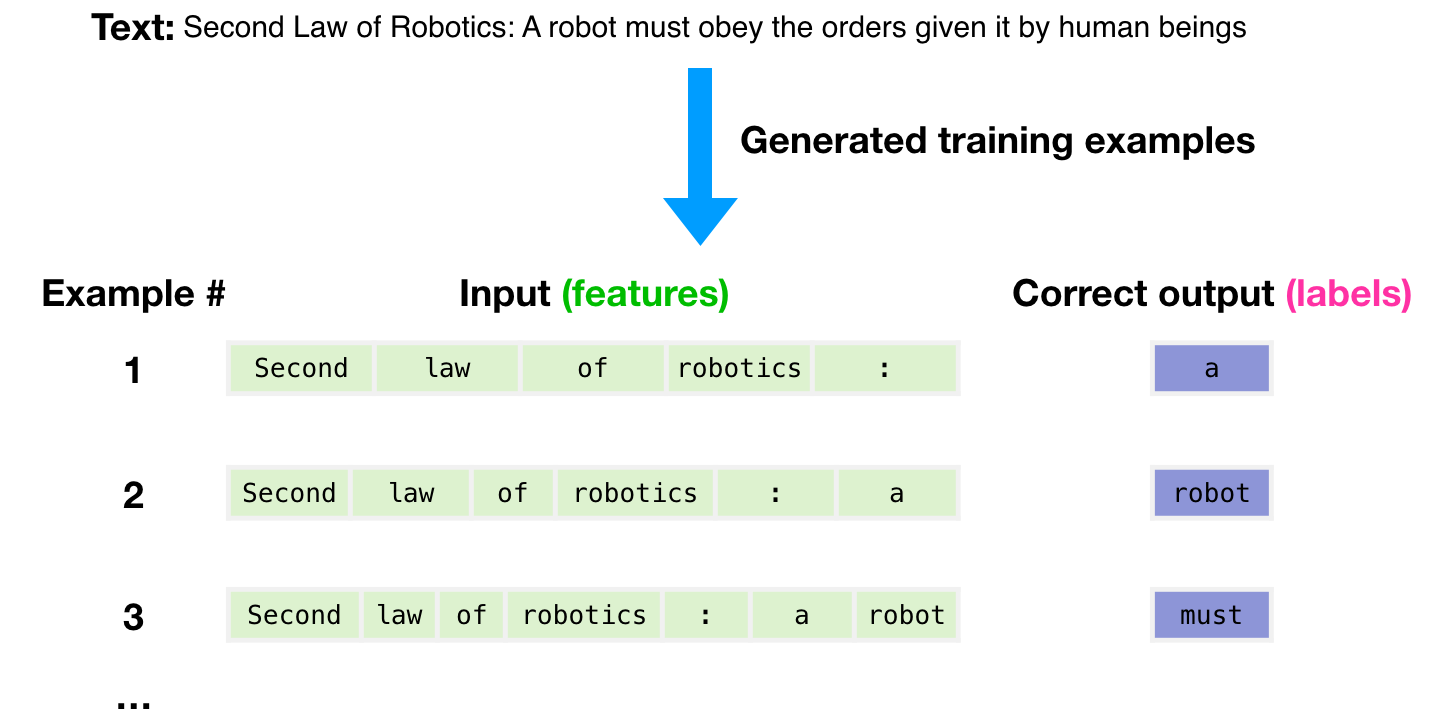
텍스트의 3000억개의 토큰 규모의 데이터셋이 모델을 위한 훈련 예제를 생성하기 위해 사용됩니다. 예를 들어, 맨 위 그림의 하나의 문장에서 생성된 3개의 훈련 예제 입니다. The dataset of 300 billion tokens of text is used to generate training examples for the model. For example, these are three training examples generated from the one sentence at the top.
모든 텍스트에 대해 윈도우를 슬라이드(slide)하면서, 많은 예제들을 만들어내는 것을 볼 수 있습니다. You can see how you can slide a window across all the text and make lots of examples.
모델을 예제와 함께 표현했습니다. 우리는 모델에게 feature만을 보여주고, 다음 단어(word)를 예측하도록 요청합니다. The model is presented with an example. We only show it the features and ask it to predict the next word.
모델의 예측이 틀리면, 우리는 모델의 예측의 error를 계산하고 model을 업데이트 합니다. 그래서 다음 번에 더 나은 예측을 만들도록 합니다. The model’s prediction will be wrong. We calculate the error in its prediction and update the model so next time it makes a better prediction.
이 것을 수백만번 반복합니다. Repeat millions of times
같은 단계를 좀 더 자세히 살펴봅시다. Now let’s look at these same steps with a bit more detail.
GPT3는 한번에 하나의 토큰을 출력으로 생성합니다 (지금은 토큰이 단어라고 가정합시다). GPT3 actually generates output one token at a time (let’s assume a token is a word for now).
강조: 이 것은 GPT-3가 동작하는 설명이며, (주로 엄청나게 큰 규모의) 모델이 얼마나 참신한가에 대한 논의가 아닙니다. 여기서 설명할 아키텍처는 Generating Wikipedia by Summarizing Long Sequences 논문을 기반으로 하는 transformer decoder 모델입니다. Please note: This is a description of how GPT-3 works and not a discussion of what is novel about it (which is mainly the ridiculously large scale). The architecture is a transformer decoder model based on this paper https://arxiv.org/pdf/1801.10198.pdf
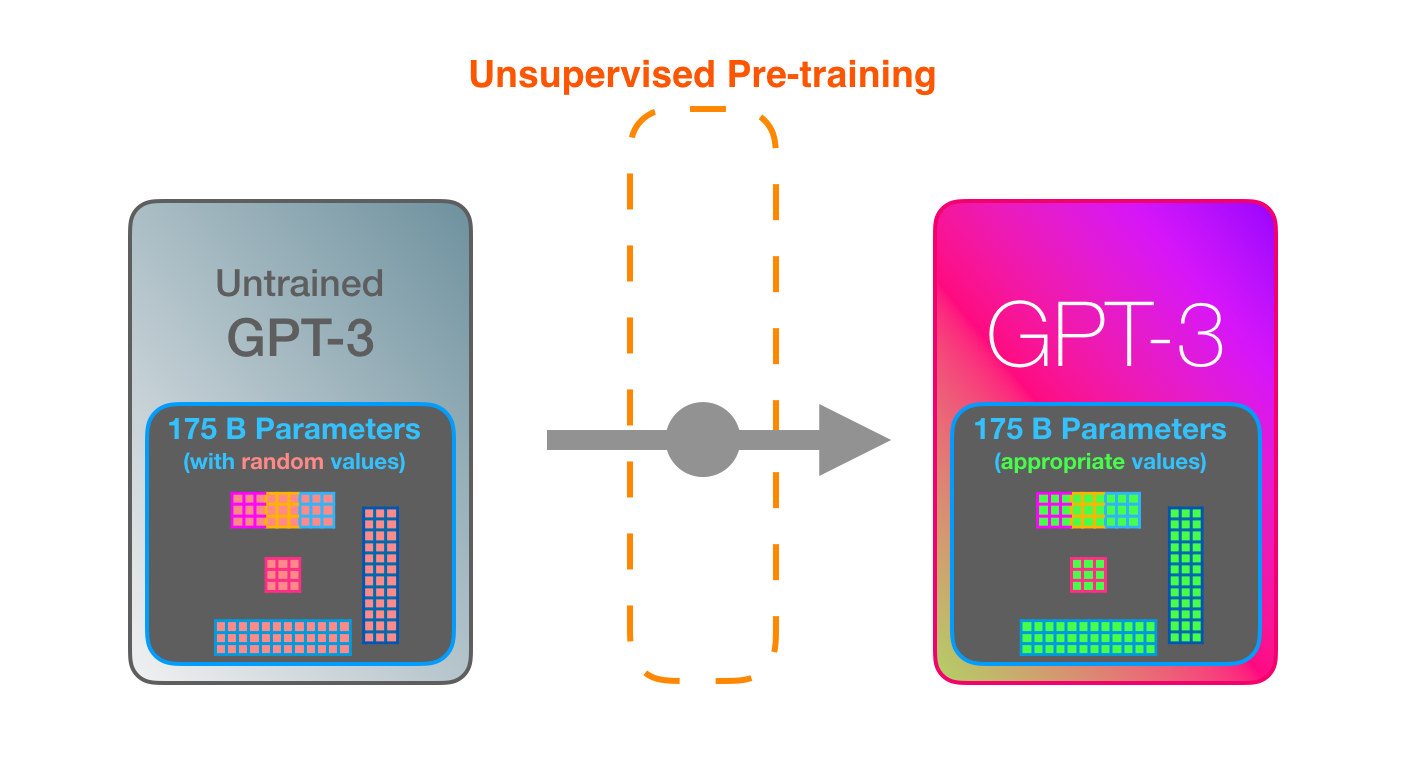
GPT3는 거.대.합니다. (파라미터라고 불리는) 1750억개 (175 billion)의 숫자를 훈련시켜 학습한 내용을 인코딩합니다. 이 숫자들은 각 실행(학습/평가/추론 등 모든 종류의 실행)에서 생성할 토큰을 계산하는데 사용됩니다. GPT3 is MASSIVE. It encodes what it learns from training in 175 billion numbers (called parameters). These numbers are used to calculate which token to generate at each run.
훈련되지 않은 모델은 임의의 파라미터 값을 갖습니다. 훈련은 더 나은 예측을 하게 만드는 값을 찾습니다. The untrained model starts with random parameters. Training finds values that lead to better predictions.
이 숫자들은 모델 안의 수백개의 matrix들의 일부입니다. 예측은 대부분 많은 횟수의 matrix 곱셈입니다. These numbers are part of hundreds of matrices inside the model. Prediction is mostly a lot of matrix multiplication.
제 AI 소개 유투브 영상에서, 한 개의 파라미터를 갖는 단순한 ML 모델을 설명했습니다. 175B이라는 가공할만한 이 파라미터에 대해 풀기(unpack)에 좋은 시작 지점이 될 것입니다. In my Intro to AI on YouTube, I showed a simple ML model with one parameter. A good start to unpack this 175B monstrosity.
이러한 파라미터가 어떻게 분포되고 사용되는지 밝히기 위해, 우리는 모델 안을 열어보고 살펴볼 필요가 있습니다. To shed light on how these parameters are distributed and used, we’ll need to open the model and look inside.
GPT3는 2048 토큰을 입력으로 받아들일 수 있습니다. 그 것을 “컨텍스트 윈도우”라고 합니다. 이 것은, 토큰들이 처리될 2048개의 경로가 있음을 의미합니다. GPT3 is 2048 tokens wide. That is its “context window”. That means it has 2048 tracks along which tokens are processed.
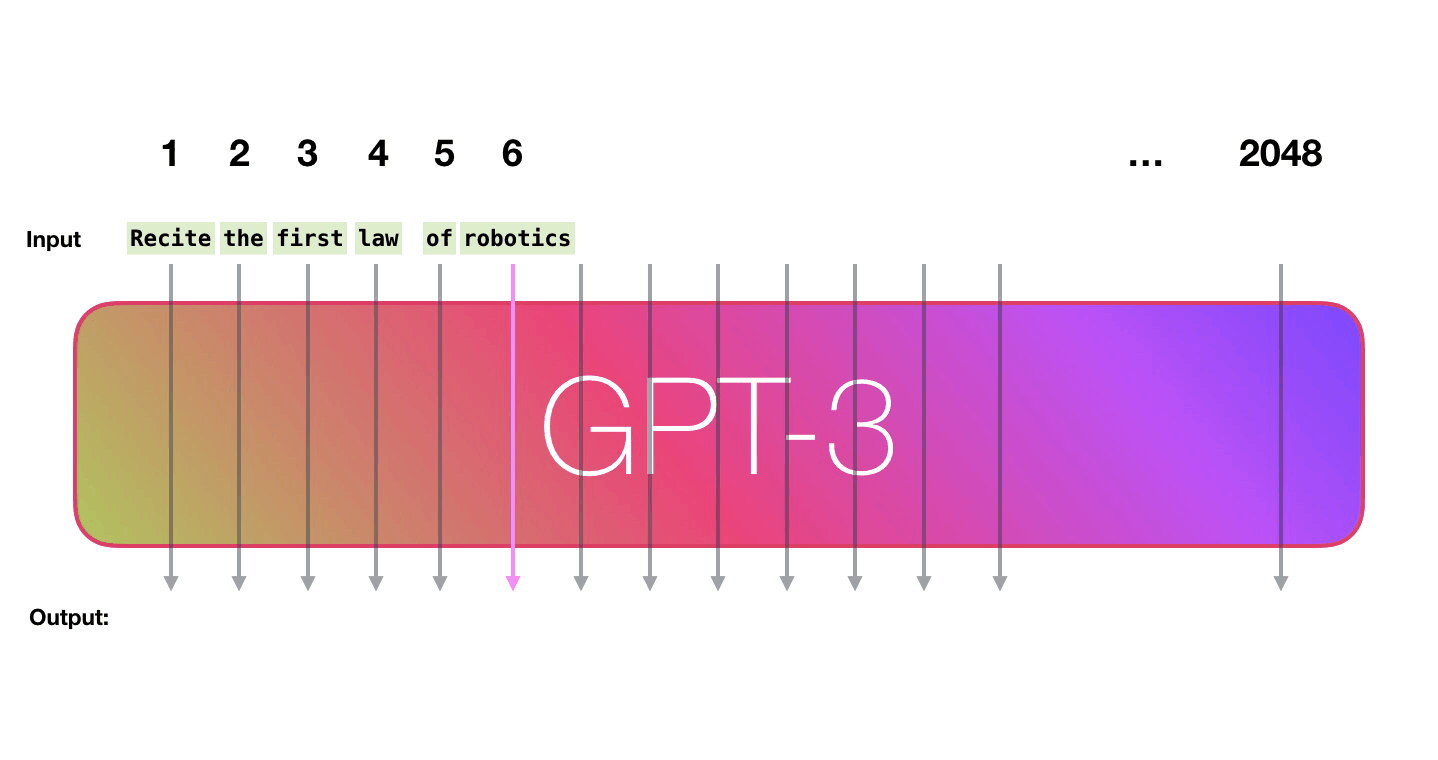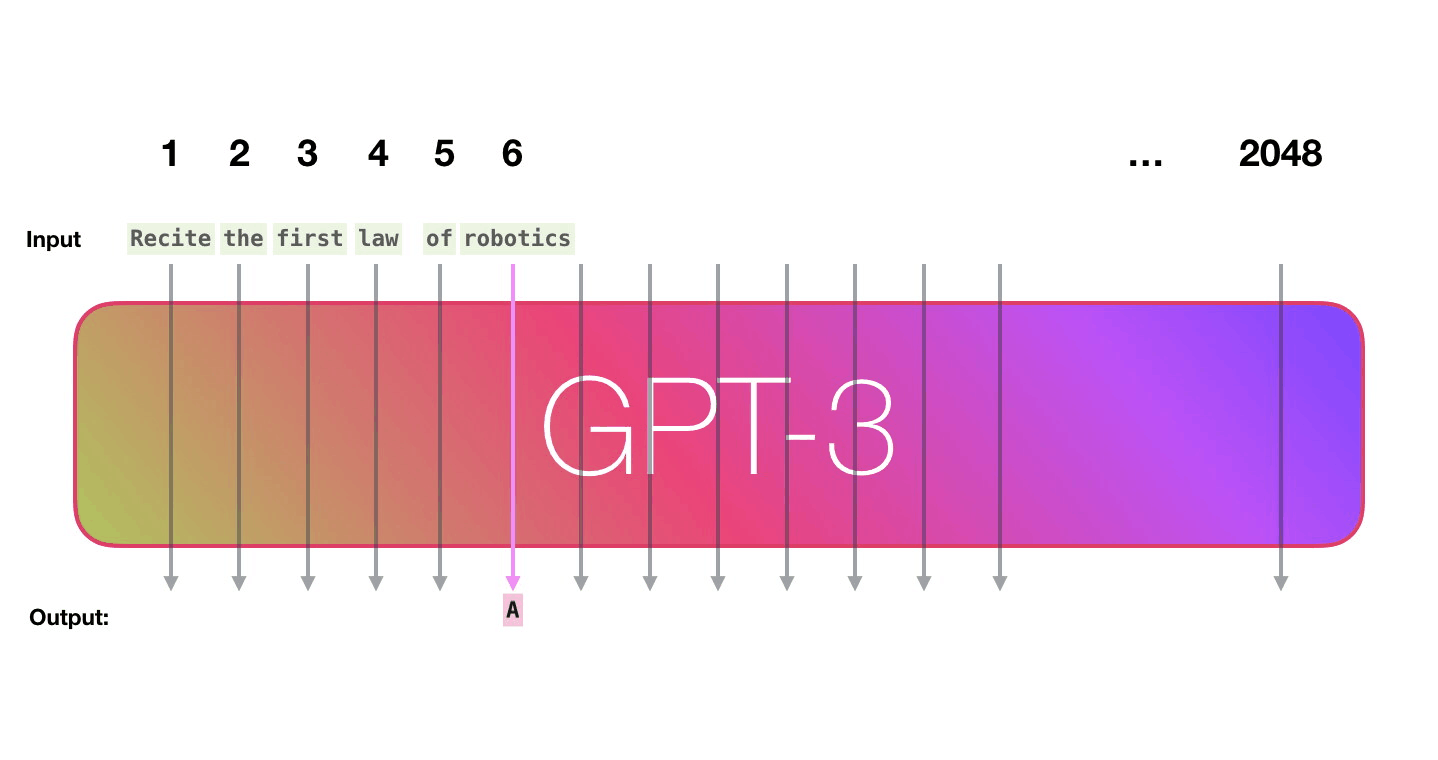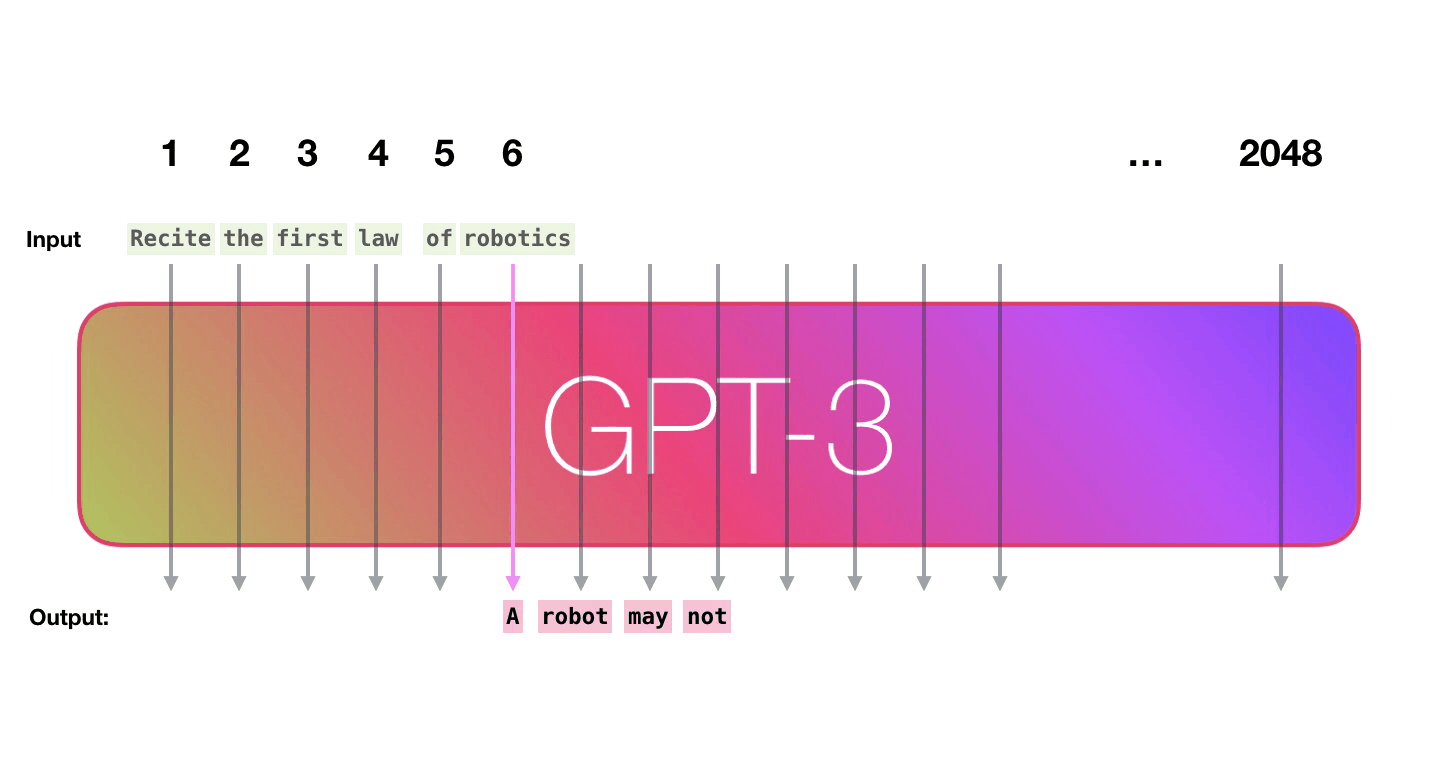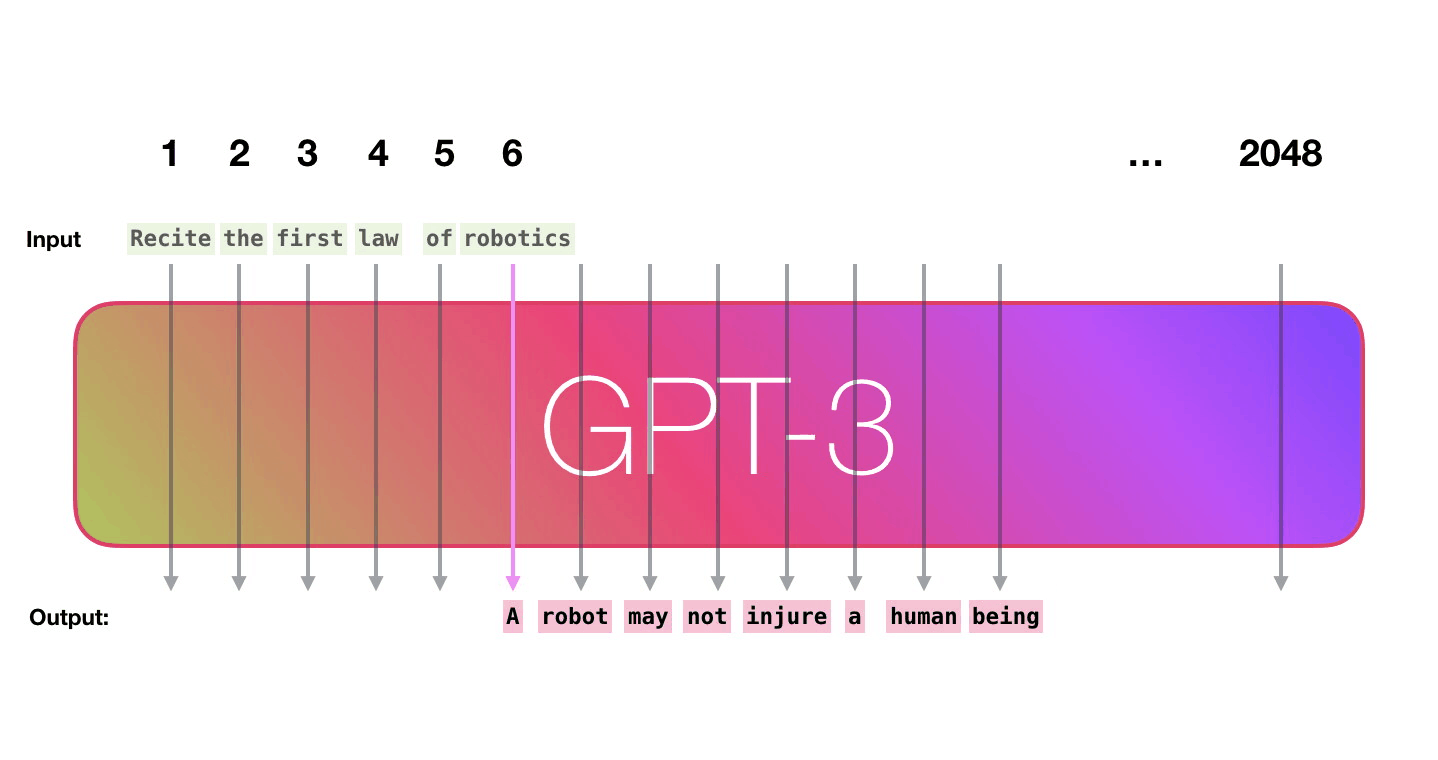
보라색 경로를 따라가 봅시다. 시스템은 어떻게 “robotics”를 처리하고 “A”를 생성할까요? Let’s follow the purple track. How does a system process the word “robotics” and produce “A”?
상위레벨 단계: High-level steps:
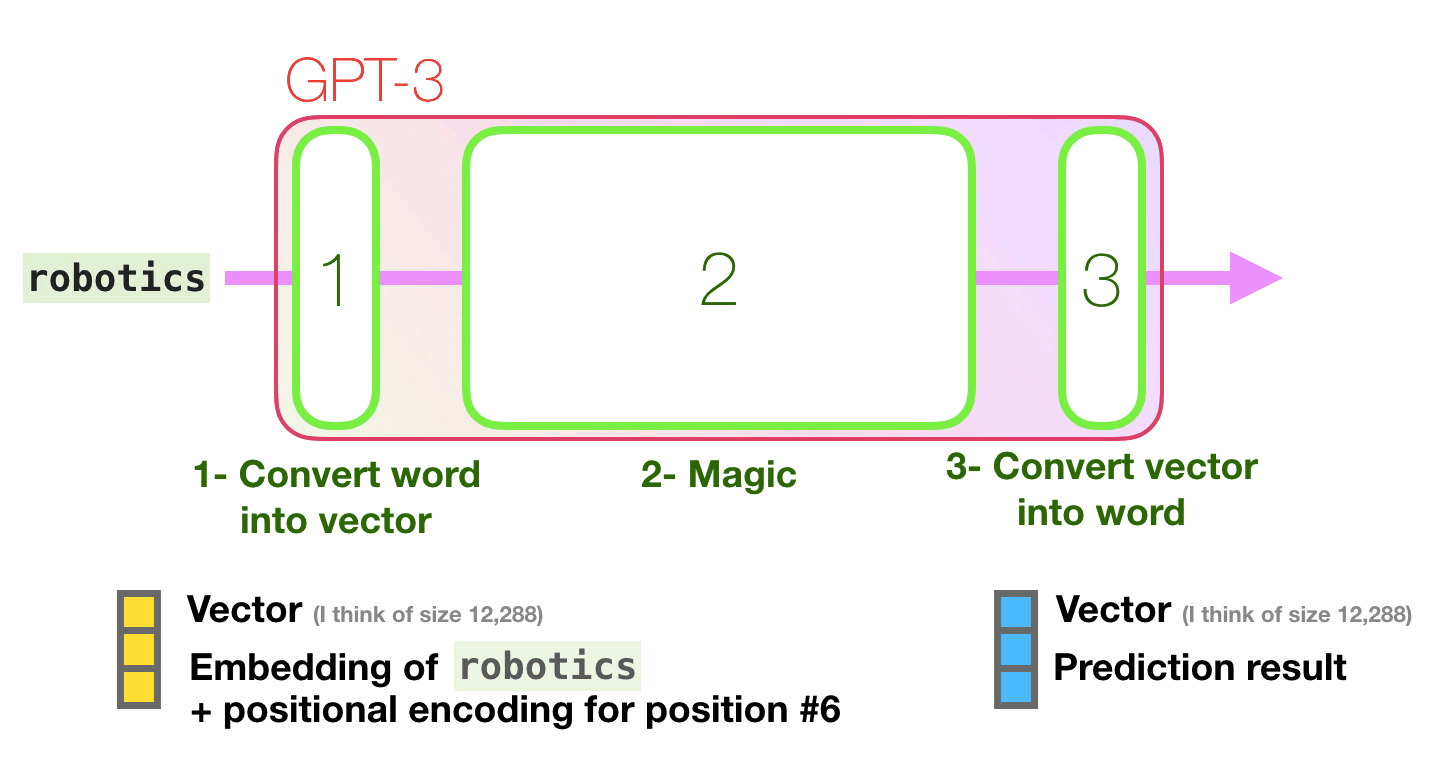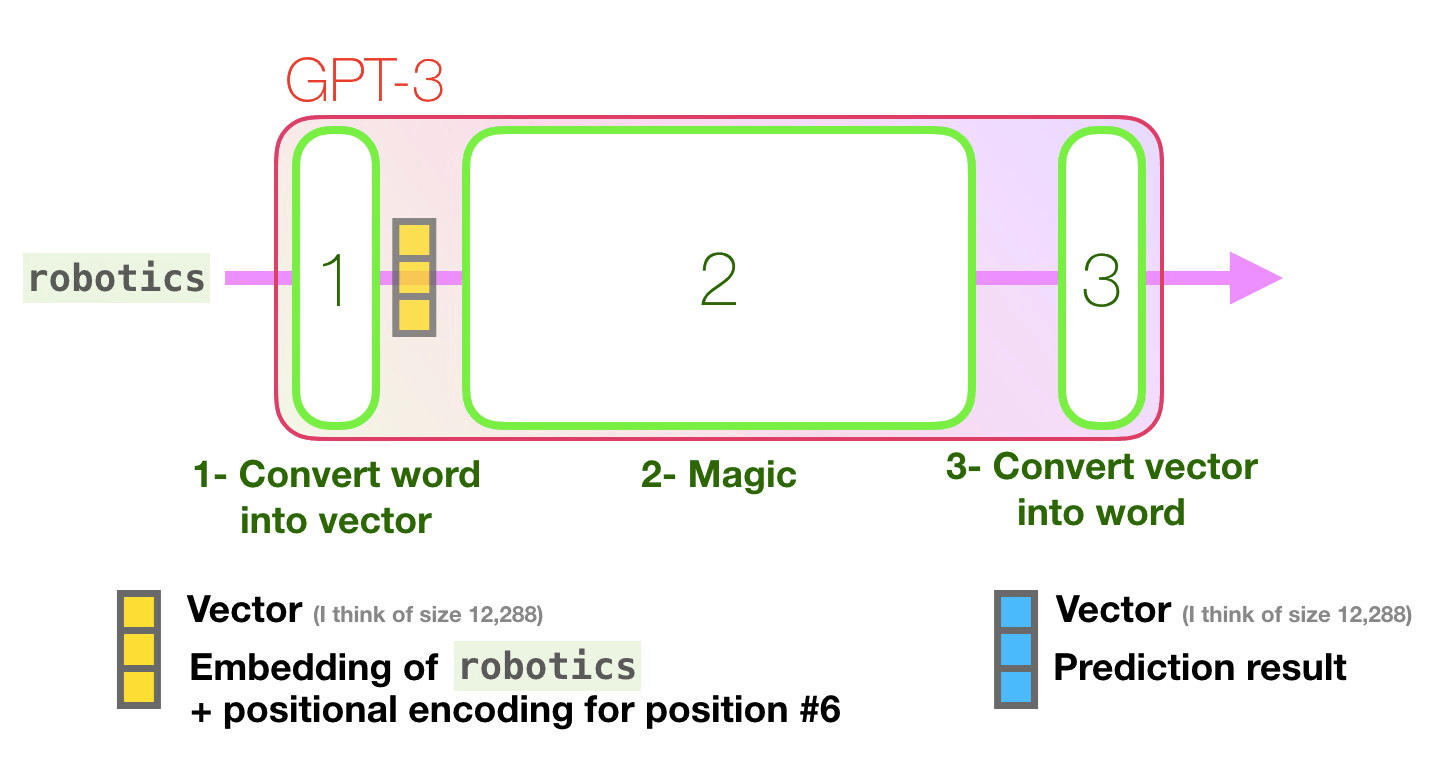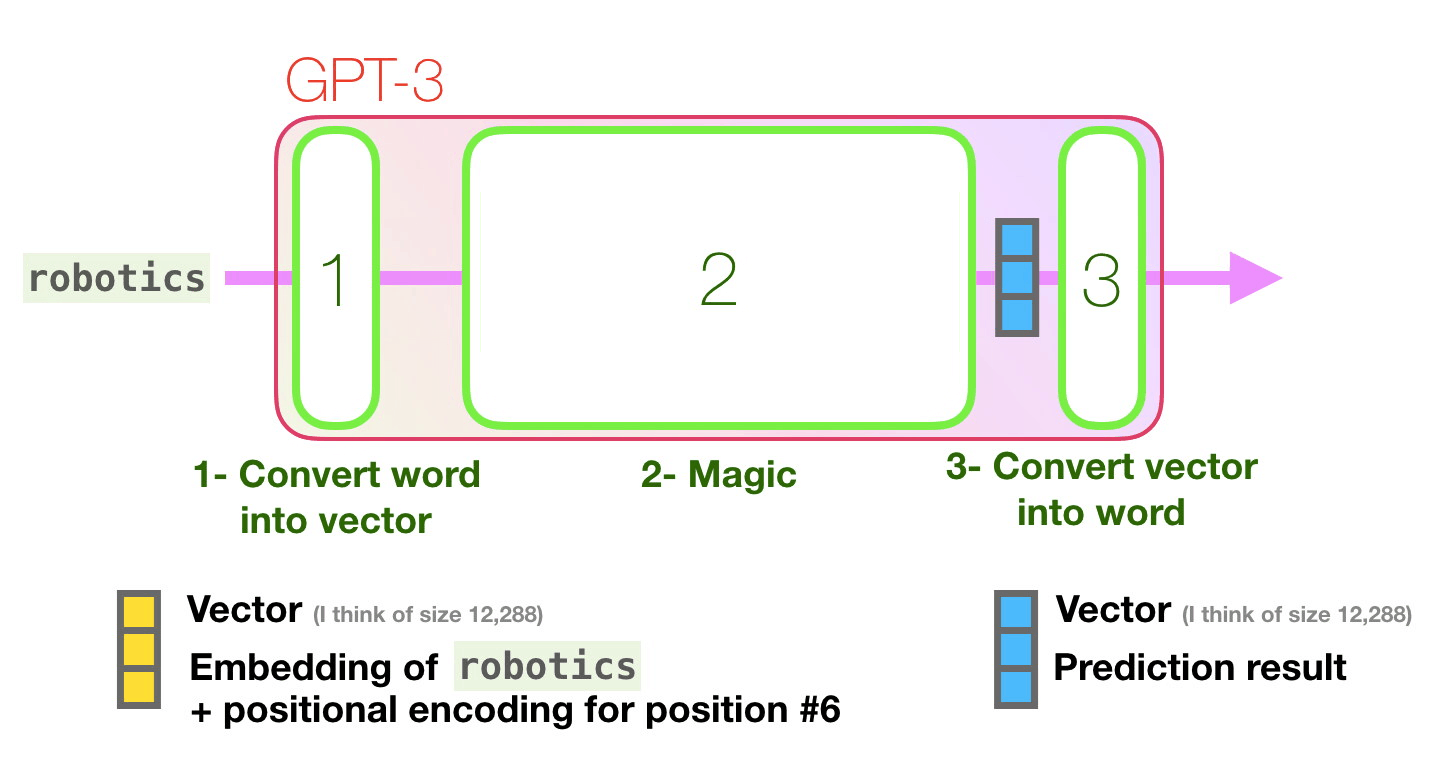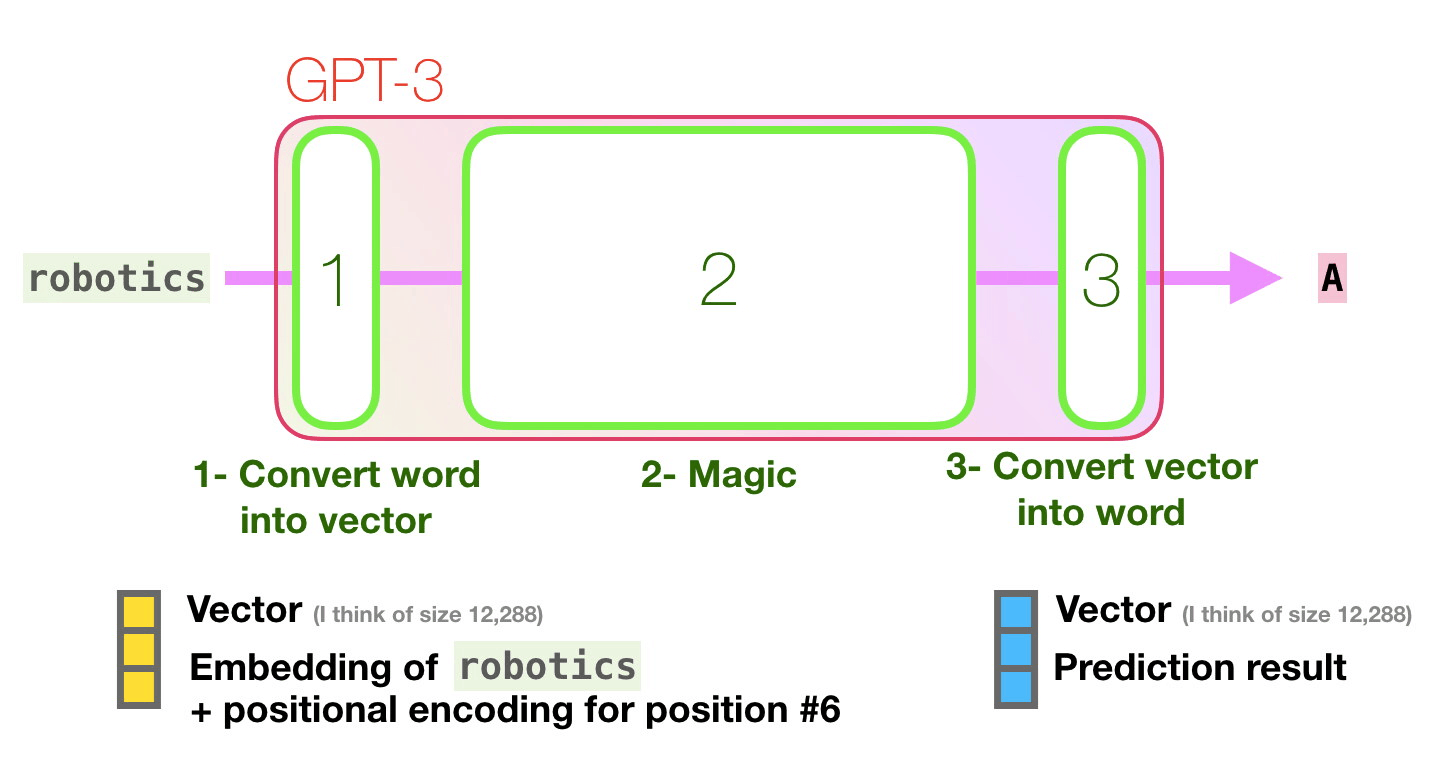
- 단어를 단어를 표현(representing)하는 vector(숫자의 나열/리스트)로 변환합니다.
- 예측을 수행합니다.
- vecor를 단어로 변환합니다.
- Convert the word to a vector (list of numbers) representing the word
- Compute prediction
- Convert resulting vector to word </span>
GPT3의 중요한 계산은 96개의 transformer decoder 레이어의 층(stack) 안에서 일어납니다. The important calculations of the GPT3 occur inside its stack of 96 transformer decoder layers.
모든 레이어가 보이죠? 이 것이 “딥러닝”의 “깊이(depth)” 입니다. See all these layers? This is the “depth” in “deep learning”.
이 레이어들 각각이, 계산을 위한 각자의 18억개(1.8B)의 파라미터를 가지고 있습니다. 여기가 바로 “마법”이 일어나는 곳 입니다. 이 과정의 상위 레벨 모습은 아래와 같습니다: Each of these layers has its own 1.8B parameter to make its calculations. That is where the “magic” happens. This is a high-level view of that process:
decoder 내부의 모든 것에 대한 자세한 설명은 제 블로그 포스트 The Illustrated GPT2에서 보실 수 있습니다. You can see a detailed explanation of everything inside the decoder in my blog post The Illustrated GPT2.
GPT3와의 차이점은 dense와 sparse self-attention layers가 번갈아가며 구성되어 있다는 것입니다. The difference with GPT3 is the alternating dense and sparse self-attention layers.
이 것은 입력의 엑스레이 이미지이며, GPT3의 응답(“Okay human”)입니다. 모든 토큰이 전체 레이어 층을 따라 흐르는 것에 주목하세요. 우리는 앞쪽의 단어들의 출력에 신경쓰지 않습니다. 입력이 완료되었을 때, 출력에 신경쓰기 시작합니다. 우리는 (출력으로 나온) 모든 단어를 모델에 다시 공급(feed)합니다. This is an X-ray of an input and response (“Okay human”) within GPT3. Notice how every token flows through the entire layer stack. We don’t care about the output of the first words. When the input is done, we start caring about the output. We feed every word back into the model.
리액트 코드 생성 예제에서, 이 글의 설명 파트는 설명=>코드의 몇가지 예제 이외의 입력 프롬프트 (녹색)가 될 것이라 생각합니다. 그리고 리액트 코드는 이 그림에서 분홍색 토큰들처럼, 토큰 단위로, 생성이 될 것입니다. In the React code generation example, the description would be the input prompt (in green), in addition to a couple of examples of description=>code, I believe. And the react code would be generated like the pink tokens here token after token.
제 가정은, 마중물(priming) 예제와 설명이 예제와 결과를 구분하는 특정 토큰과 함께 입력으로 추가된다는 것 입니다. 그런 다음 모델로 공급(feed) 됩니다. My assumption is that the priming examples and the description are appended as input, with specific tokens separating examples and the results. Then fed into the model.

이렇게 동작하는 것은 인상적입니다. 아직 GPT3를 위한 fine-tuning은 나오지도 않았습니다. 이 가능성은 더욱 놀랍습니다. It’s impressive that this works like this. Because you just wait until fine-tuning is rolled out for the GPT3. The possibilities will be even more amazing.
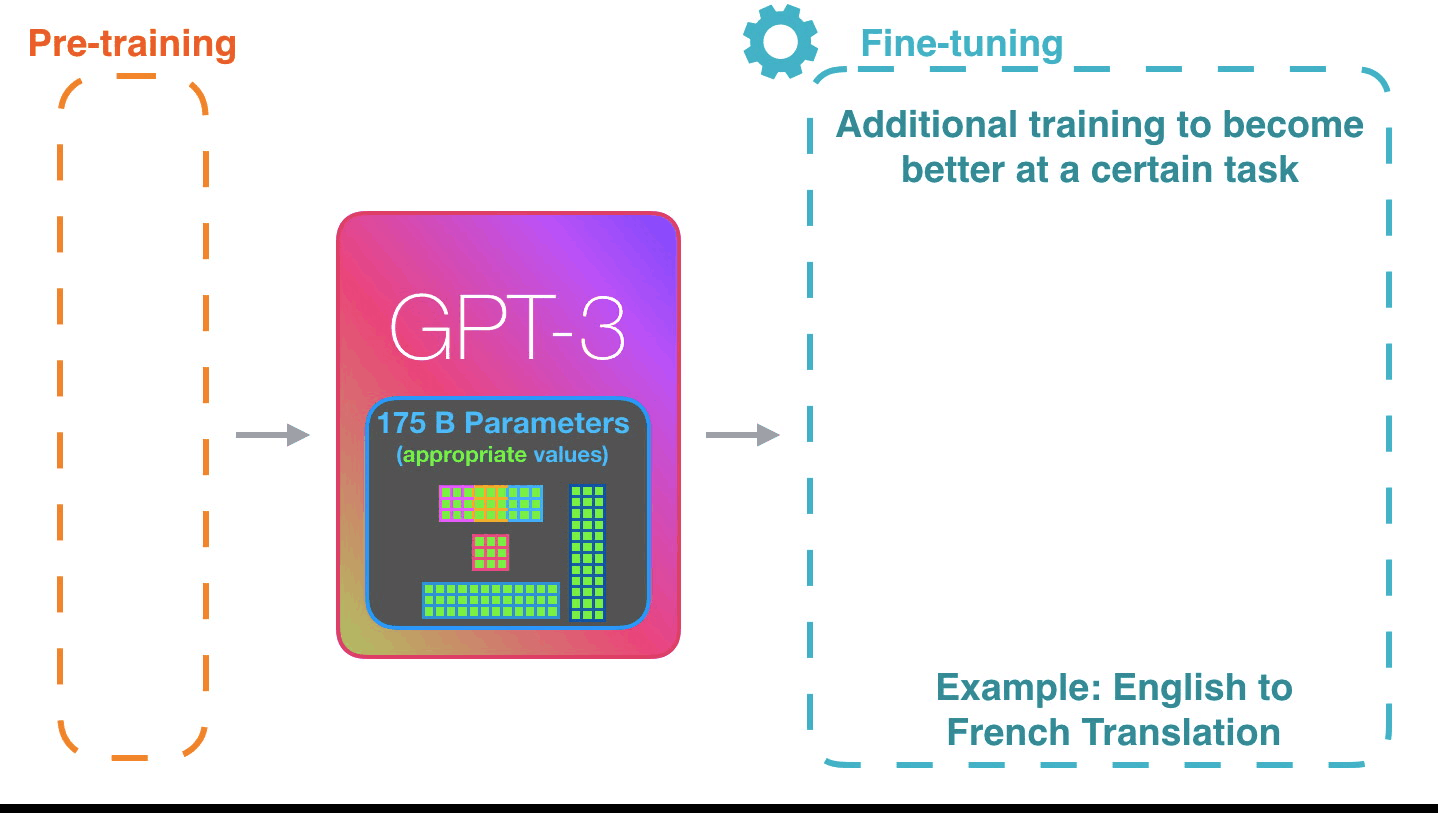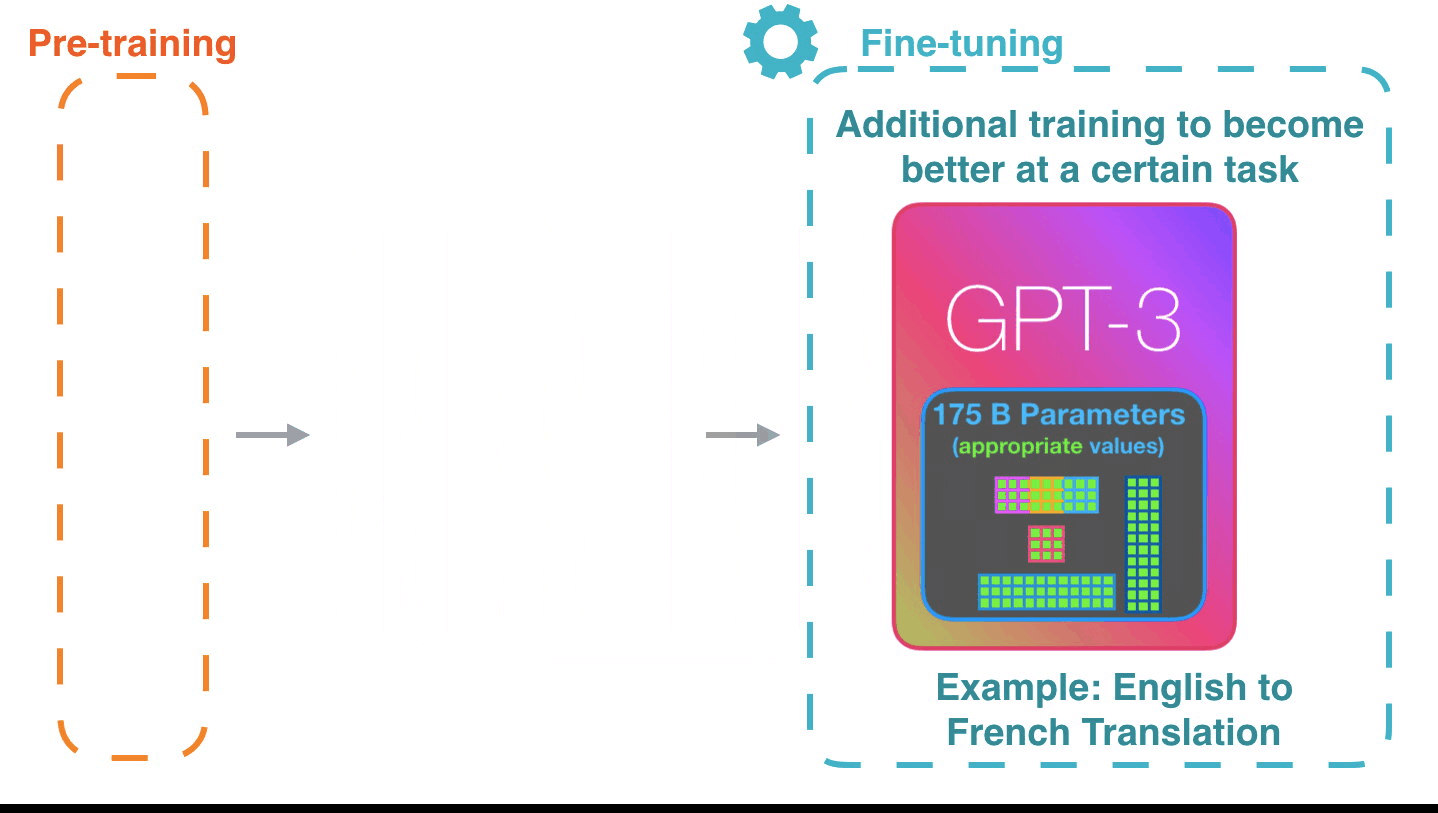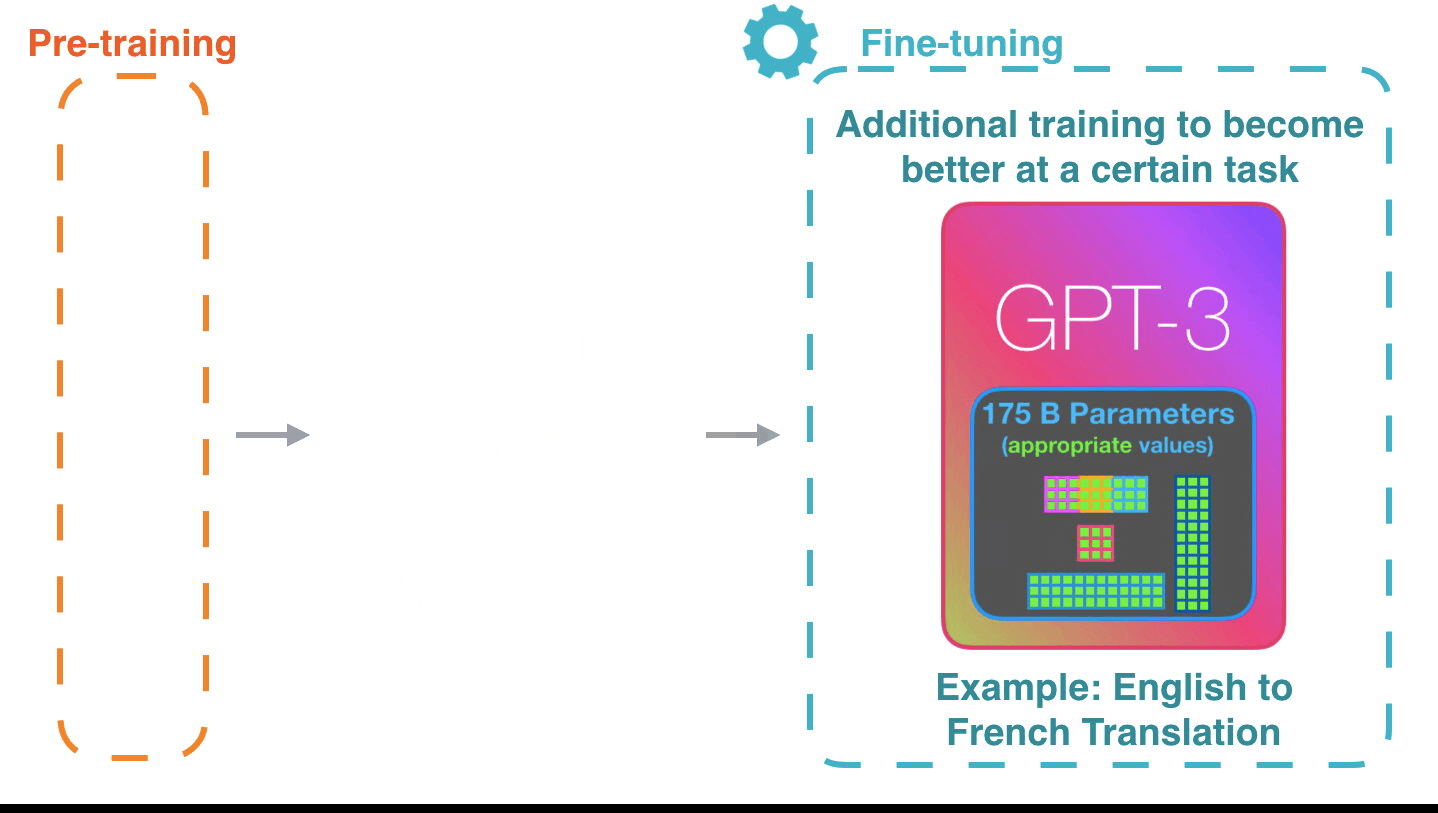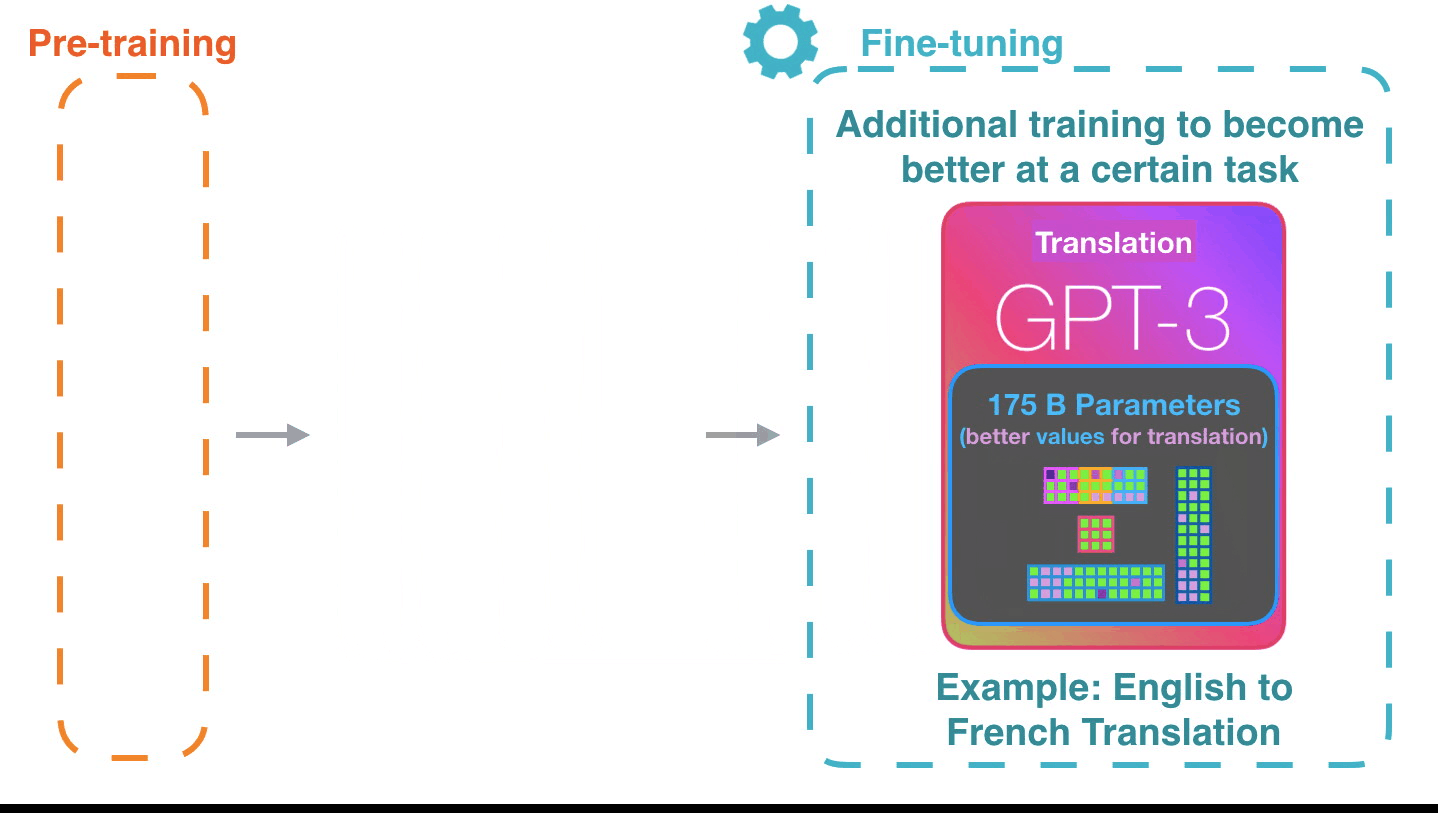
Fine-tuning은 모델의 weight를 실제로 업데이트 해서 특정 태스크에 대한 모델(의 성능)을 더 좋게 만듭니다. Fine-tuning actually updates the model’s weights to make the model better at a certain task.
추가 정보.
- 이 글은 GPT2에 대해 이해하기 쉽게 그림으로 설명한 포스팅을 저자인 Jay Alammar님의 허락을 받고 번역한 글 입니다. 원문은 How GPT3 Works - Visualizations and Animations에서 확인하실 수 있습니다.
- 원서/영문블로그를 보실 때 term에 대한 정보 호환을 위해, 이 분야에서 사용하고 있는 단어, 문구에 대해 가급적 번역하지 않고 원문 그대로 두었습니다. 그리고, 직역 보다는 개념이나 의미에 대한 설명을 쉽게 하는 문장 쪽으로 더 무게를 두어 번역 했습니다. 번역에 대한 의견이나 수정 사항은 아래 댓글 창에 남겨주세요.
- 번역문에 대응하는 영어 원문을 보고싶으신 분들을 위해 찬님께서 만들어두신 툴팁 도움말 기능(해당 문단에 마우스를 올리면 (모바일의 경우 터치) 원문을 확인할 수 있는 기능)을 가져와서 적용했습니다. 감사합니다.